데이터 출처 : www.kaggle.com/mahirahmzh/starbucks-customer-retention-malaysia-survey
Starbucks Customer Survey
Survey from Malaysia on Starbucks Customer Behaviour
www.kaggle.com
github 주소 : github.com/sangHa0411/DataScience/blob/main/Starbucks_Survey.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
A step-by-step guide for creating advanced Python data visualizations with Seaborn / Matplotlib
Although there’re tons of cool visualization tools in Python, Matplotlib + Seaborn still stands out for its capability to create and…
towardsdatascience.com
이번 포스팅에서는 스타벅스 설문조사 데이터를 시각화하는데 이제까지 자주 사용해왔던 matplotlib을 사용하는 것이 아니라 seaborn을 활용하면서 시각화해볼 것입니다.
seaborn에 있는 많은 그래프그리는 방법을 다양하게 다루어보겠습니다.
먼저 데이터를 불러오겠습니다.
데이터 구조상 Column에 질문이 있는 것을 확인할 수 있습니다. 따라서 이를 숫자로 변경하고 질문 내용은 Dictionary에 저장하겠습니다.

question_Dict의 key는 질문 번호가 , value는 질문 내용이 저장되어있는 것을 확인할 수 있습니다.
그리고 질문 내용을 제외하고 숫자만으로 data의 column의 이름을 변경합니다,

1. sns.countplot
저는 이산적인 속성을 대상으로 해당 속성의 갯수를 세서 bar graph를 그리는 sns,countplot를 사용해보도록 하겠습니다.
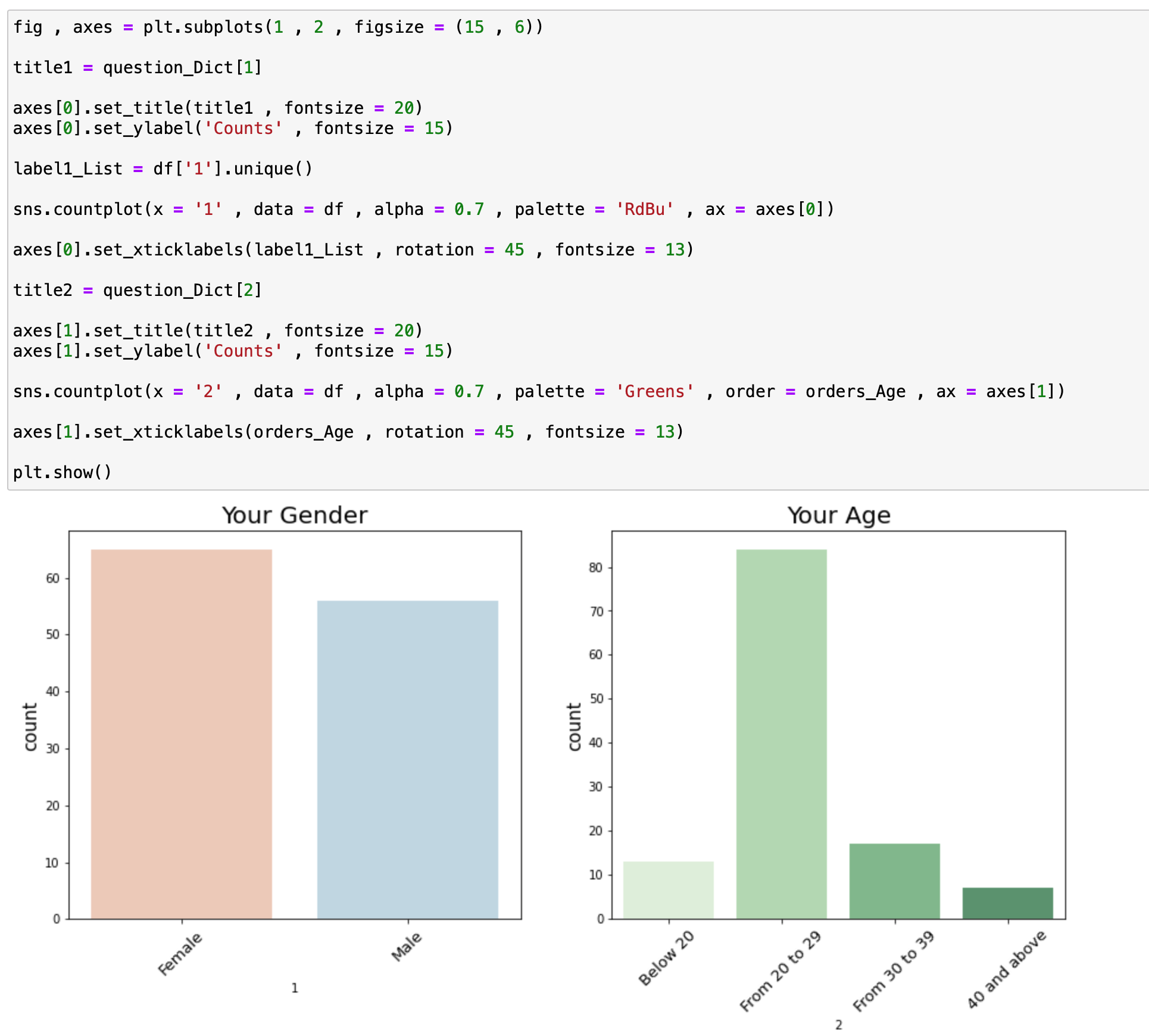
하나의 화면에 성별 속성과 나이 속성을 나누어서 그렸으며 핵심 코드는 아래와 같습니다.
sns.countplot(x = '1' , data = df , alpha = 0.7 , palette = 'RdBu' , ax = axes[0])x인자는 속성 , data에는 pandas 데이터 , alpha는 Bar의 농도 , Palette 는 색상을 의미합니다.
자세한 과정은 위 github주소에 가시면 확인하실 수 있습니다.
여기서 hue인자를 추가로 해서 비교분석할 수 있게끔 Bar Graph를 그릴 수 있습니다.
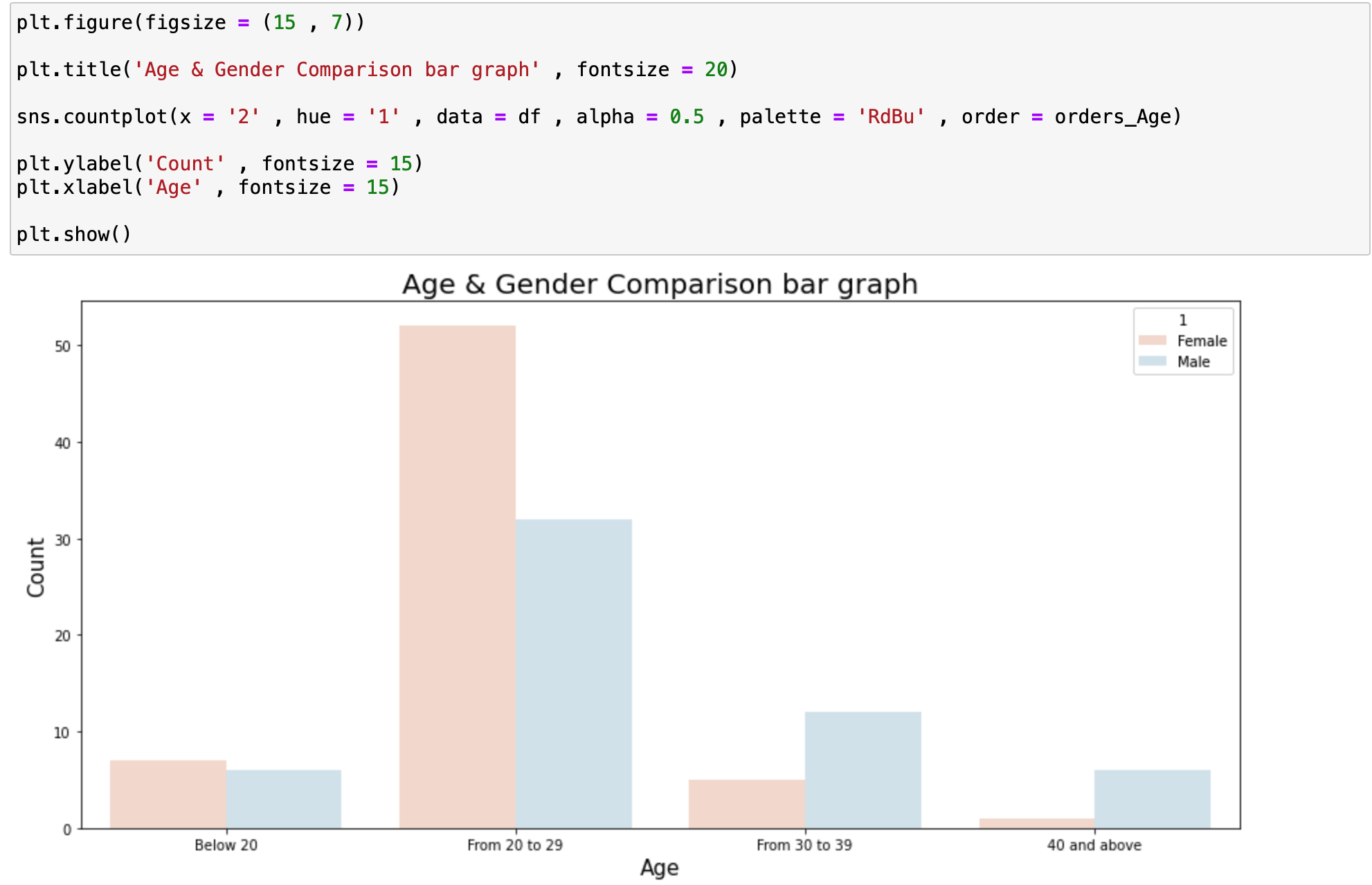
핵심 코드는 아래와 같습니다.
sns.countplot(x = '2' , hue = '1' , data = df , alpha = 0.5 , palette = 'RdBu' , order = orders_Age)원래는 나이속성을 나누어서 그래프를 그리는데 각 속성에 hue로 입력된 속성으로 분류해서 Bar Graph를 그린 것을 확인할 수 있습니다.
2. sns.lineplot
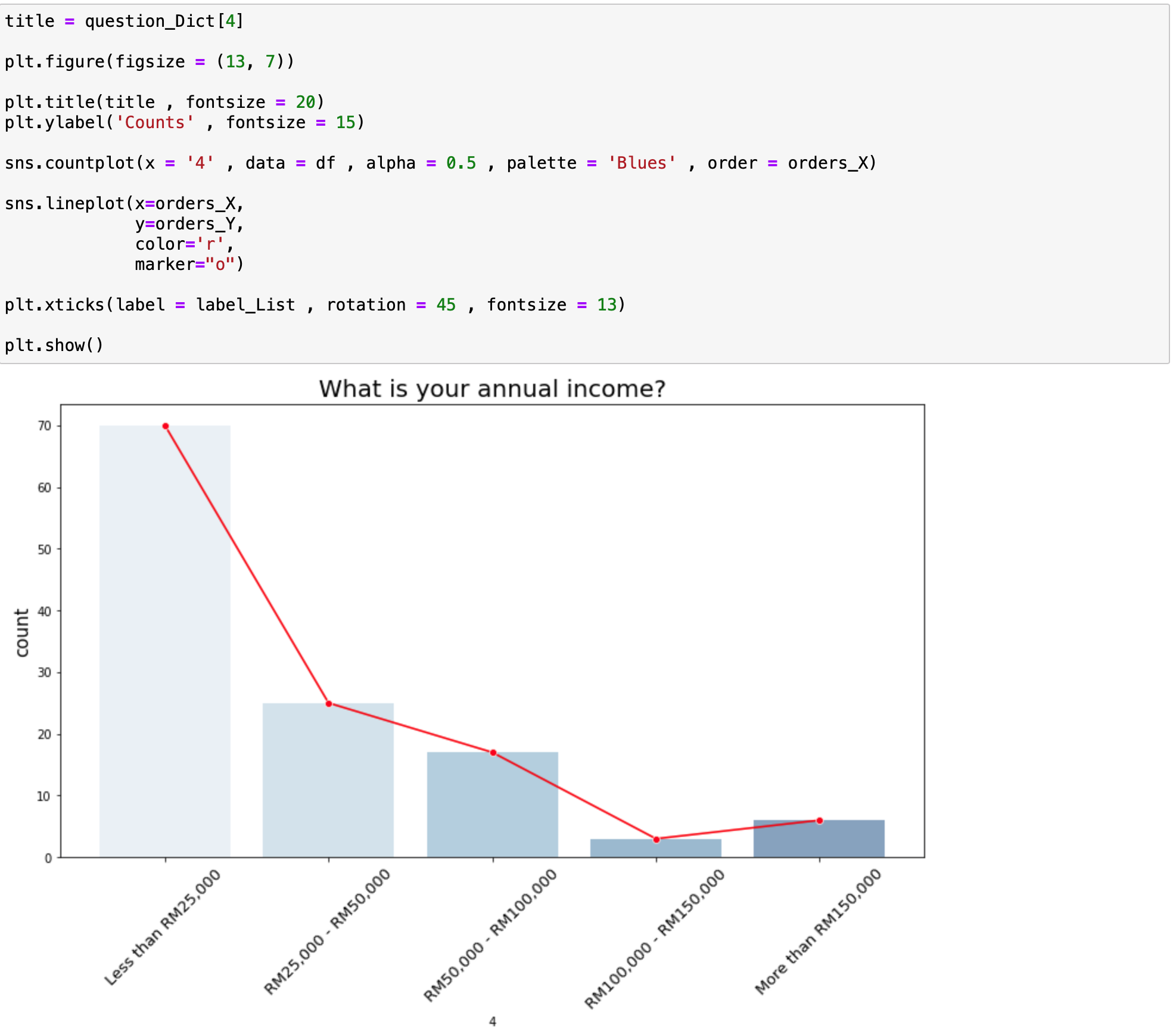
앞서서 정리한 sns.countplot 을 이용해서 그린 bar garph에 각 bar의 값을 선으로 이은 line graph를 같이 그려보았습니다.
핵심 코드는 다음과 같습니다.
sns.lineplot(x=orders_X,
y=orders_Y,
color='r',
marker="o")x , y 값을 인자로 입력해야 하는데 x , y,의 인자로 들어간 리스트는 다음과 같습니다.
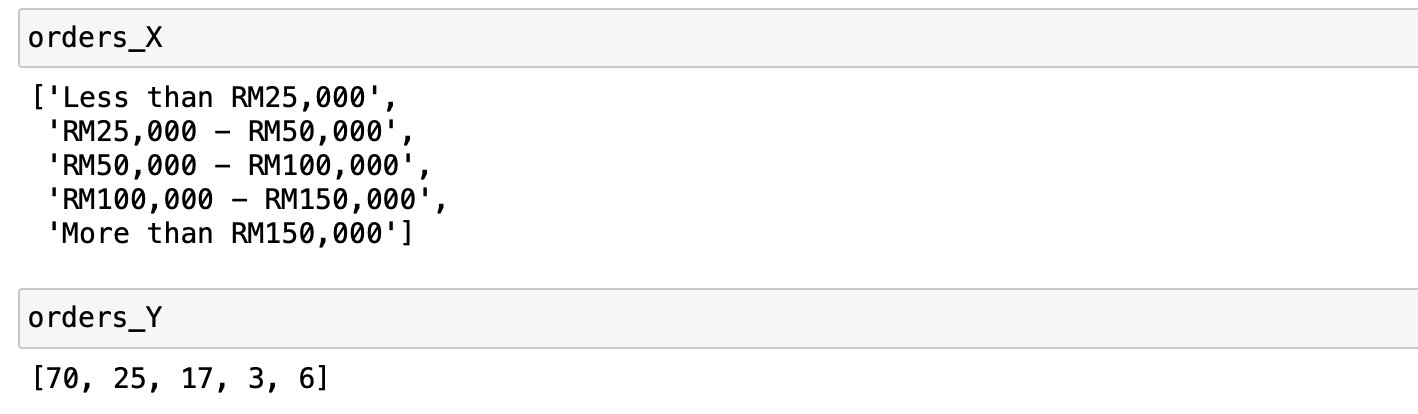
정리하면 위와 같은 경우는 X는 각 속성에 해당되는 값이고 Y는 해당 속성의 데이터의 갯수로 해서 line graph를 그린 것입니다.
3. sns.kdeplot
아래의 첫번째 그래프 Pie Chart는 스타벅스의 퀄리티가 얼마나 되는가에 대한 1,2,3,4,5 로 평점을 매긴 데이터의 비율을 파악하기 위한 데이터입니다.

여기에 이전에는 sns,coutplot을 이용해서 bar graph를 이용해서 그래프를 그려보았다면 이번에는 sns,kdeplot을 그려보았습니다.
sns.kdeplot(x = '12' , data = df , fill = True , alpha = 0.1 , hue = '1' , palette = 'Set1')그래프의 y 값이 Density인 것을 확인할 수 있습니다. 그리고 여성의 경우 평정을 3에 많이 매긴 것을 확인할 수 있지만 남성의 경우 평점을 주로 4점에 매긴 것을 바로 확인할 수 있습니다.
sns,countplot 을 통해서 그린 bar graph는 이산적인 속성에 대해서 각 갯수를 파악하기 쉬었다면 sns.kdeplot을 통해서 연속적인 속성에 대해서 어느 값이 주를 이루는지 파악하기 용이한 것을 확인할 수 있습니다.
4. sns,heatmap
이번에는 스타벅스를 방문하는 고객의 연령대와 스타벅스안에 있는 시간에 대한 두 이산적인 변수에 대해서 seaborn을 이용해서 heatmap을 그려보아서 분석해보곘습니다.
sns,heatmap을 이용하기 위해서는 먼저 데이터의 구조를 변형시켜주어야 합니다.

위에 만든 데이터에 갯수를 파악해서 값을 넣어줍니다.

여기서 데이터의 구조를 변형해줍니다.

따라서 heatmap을 만들기 위해서는 index가 하나의 속성 column이 하나의 속성에 대한 데이터로 구성이 되어있고 각 쉘에는 해당 값이 있어야 한다는 것을 확인할 수 있습니다.
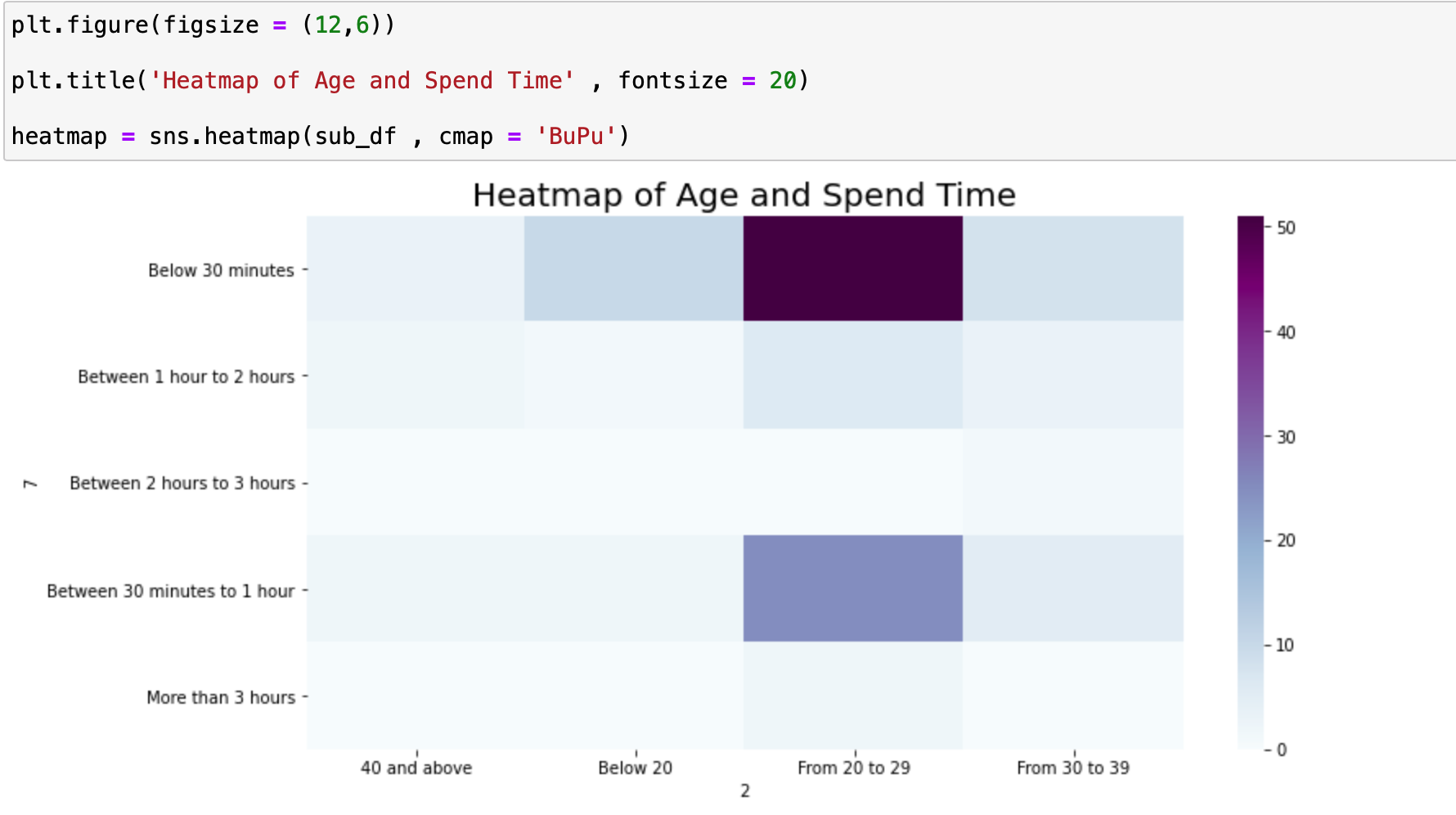
핵심 코드는 다음과 같습니다.
heatmap = sns.heatmap(sub_df , cmap = 'BuPu')
단번에 봐도 가장 짙은 색깔인 연령대가 20대 그리고 스타벅스안에서의 사용 시간은 주로 30분 미만인 속성이 가장 많은 것을 확인할 수 있습니다.
5. sns.violinplot

핵심 코드는 다음과 같습니다.
sns.violinplot(x = '2' , y = '13' , data = df , palette = 'OrRd' , ax = bottom , order = orders_Age)violinplot을 이용해서 X는 이산적인 속성인 연령대 그리고 Y는 연속적인 속성으로 여겨질 수 있는 스타벅스 가격대에 대한 평가를 인자로 입력해서 그린 그래프입니다.
이를 통해서 각 연령대별로 스타벅스 가격에 대한 평가가 어떤 값을 주가 되는지 어떻게 퍼져있는지 단번에 파악이 가능합니다.
6.sns.catplot
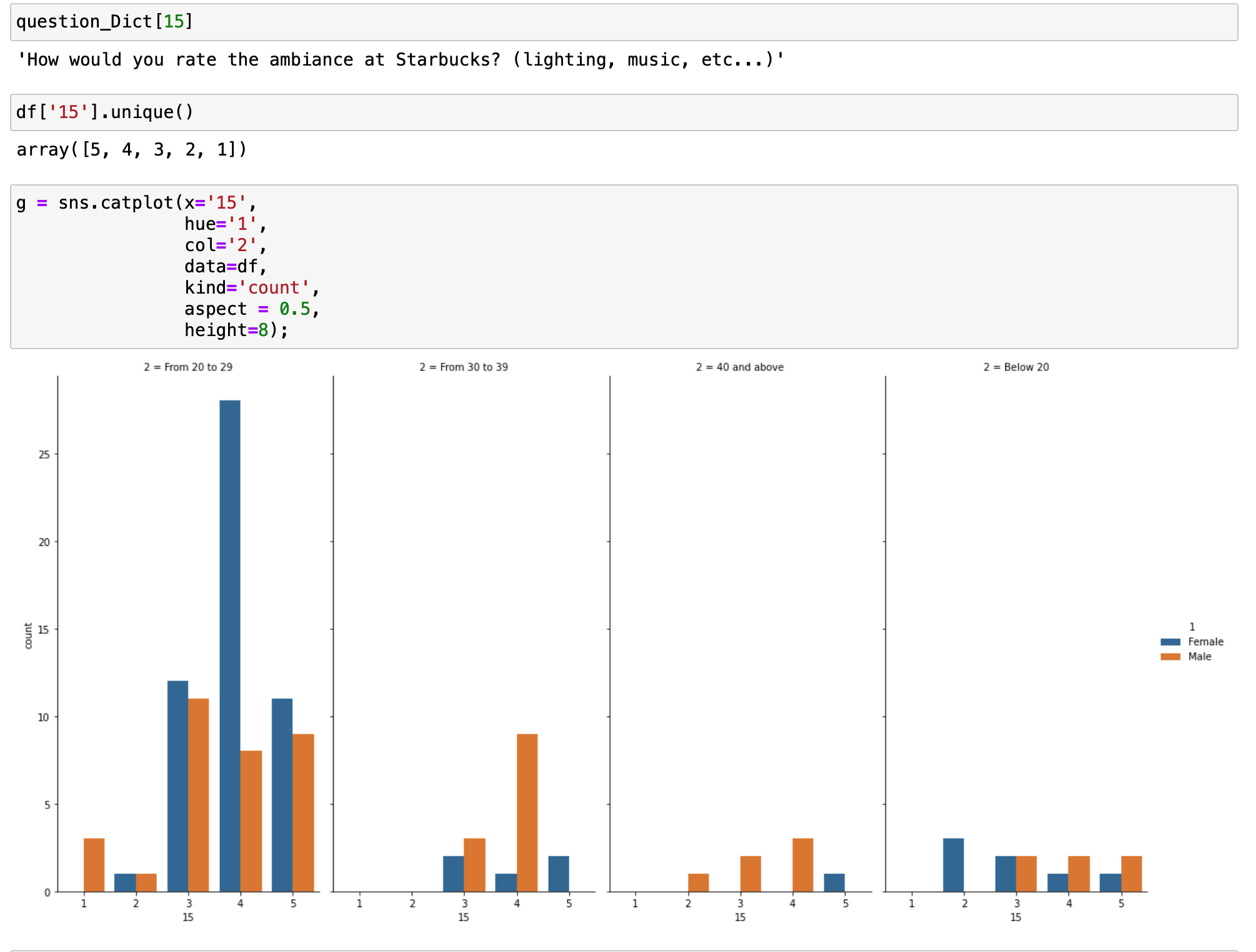
핵심코드는 다음과 같습니다.
g = sns.catplot(x='15',
hue='1',
col='2',
data=df,
kind='count',
aspect = 0.5,
height=8);x값으로 15번쨰 질문에 대한 속성 (스타벅스 카페의 분위기에 대한 평가)을 입력하고 col에는 2번째 질문 연령대에 대한 속성을 입려하고 이를 hue = 1 즉 성별에 대한 속성을 입력함으로써 그래프를 바로 그릴 수 있었습니다.
정리하자면 col로 입력된 속성대로 데이터를 나누고 나누어진 데이터는 x값으로 입력된 속성을 기준으로 그래프를 그립니다. 여기서 hue로 입력된 속성이 있다면 이를 이용해서 x로 입력된 속성을 hue 속성으로 분류해서 각 서브데이터에 대해서 그래프를 그리는 것을 확인할 수 있습니다.
5. sns.kdeplot (2D) & sns.histplot
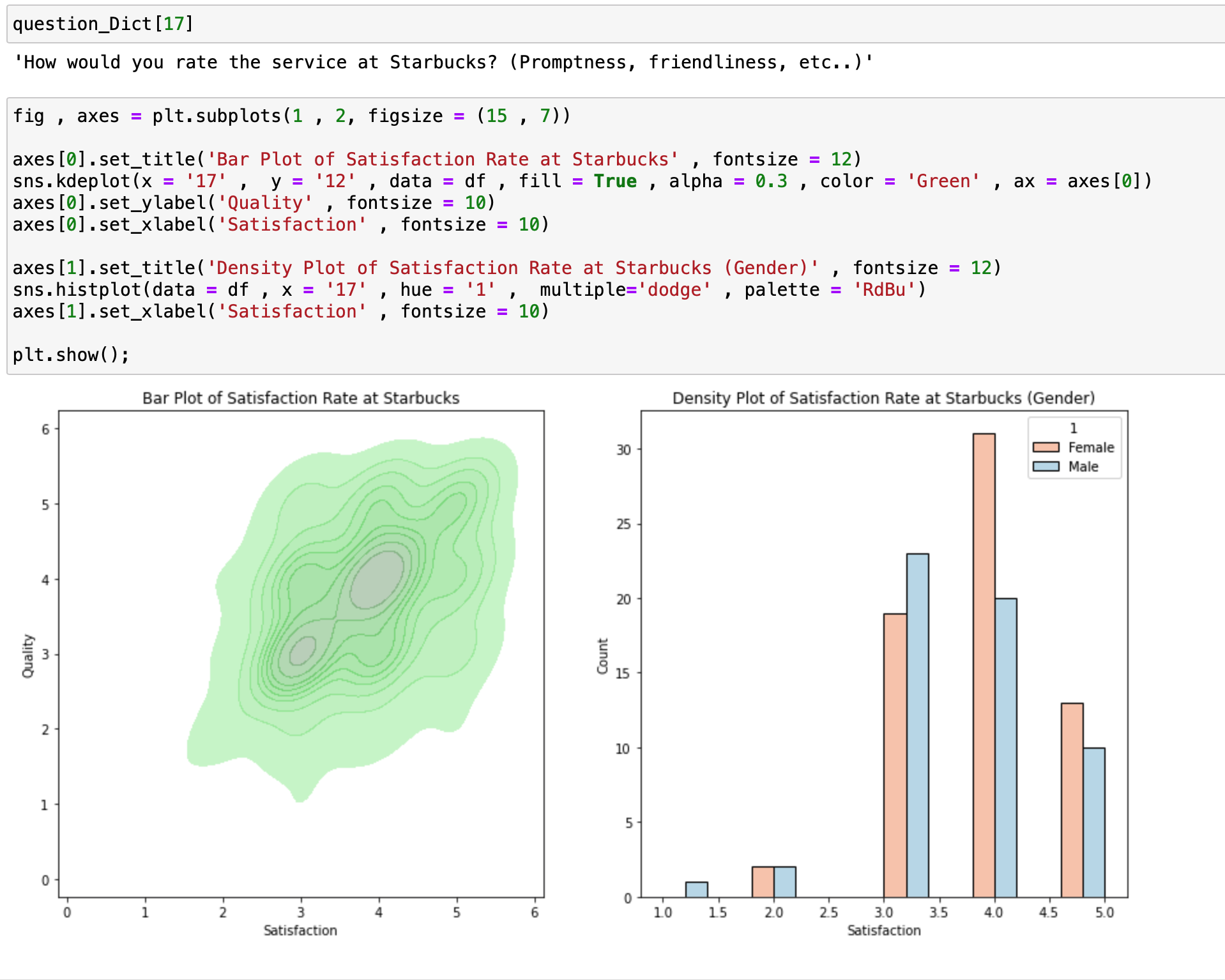
각각의 그래프에 대한 핵심코드는 다음과 같습니다.
# 2D KdePlot
sns.kdeplot(x = '17' , y = '12' , data = df , fill = True , alpha = 0.3 , color = 'Green' , ax = axes[0])
# histogram
sns.histplot(data = df , x = '17' , hue = '1' , multiple='dodge' , palette = 'RdBu')
앞서서는 오직 하나의 속성과 선택적으로 그 속성을 다른 속성으로 나누어서 kdeplot을 해보았다면 이번에는 2개의 연속적인 속성을 각각 x, y 에 입력함으로써 어디 부분이 가장 밀도가 큰지를 확인해볼 수 있게 2D로 그려보았습니다.
X는 스타벅스에 대한 만족도 , y는 스타벅스 커피에 대한 퀄리티 에 대한 각각의 평가를 입력하였습니다.
그 결과 x = 4 , y = 4 부분에 색깔이 가장 진한 것을 확인할 수 있으며 이에 해당 되는 데이터가 가장 주를 이룬다는 것을 확인할 수 있습니다.
그리고 2번째로는 히스토그램입니다. 원래 평가와 같이 1, 2, 3 , 4. 5 로 만 이루어져있기 때문에 이러한 연속적인 변수가 아닌 소수 값도 존재하는 연속적인 속성에 대해서는 각 값에 대한 bar graph로는 그리기가 어려워서 히스토그램을 이용해서 그려야 합니다.
이번에는 그저 histplot 함수를 사용해보기 위해서 위와 같은 히스토그램을 그려보았으며 1 ~ 5 로 점수가 매겨진 평가 데이터이기 때문에 그래프는 sns.countplot 함수의 결과와 거의 유사하게 그려진 것을 확인할 수 있습니다.
전체 과정과 코드는 위 github 주소에 가시면 확인하실 수 있습니다.
'Data Visualization' 카테고리의 다른 글
| Data Visualization - 구글 플레이스토어 데이터 분석 및 시각화하기 Part2 (0) | 2020.11.05 |
|---|---|
| Data Visualization - 구글 플레이스토어 데이터 분식 및 시각화하기 Part1 (0) | 2020.11.05 |
| Data Visualization - GeoPandas 이용해서 샌프란시스코 범죄 데이터 시각화하기 Part2 (0) | 2020.10.20 |
| Data Visualization - 샌프란시스코 범죄 데이터 시각화하기 Part1 (0) | 2020.10.20 |
| Data Visualization - Corona Case를 Matplotlib animation으로 그래프 그리기 (0) | 2020.10.10 |