데이터 출처 : www.kaggle.com/roshansharma/sanfranciso-crime-dataset
Sanfranciso Crime Dataset
Analyzing Crime in San Francisco
www.kaggle.com
github 주소 : github.com/sangHa0411/DataScience/blob/main/Crime%20Analysis%20Part1.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
이번 포스팅에서는 위 데이터인 Sanfranciso 범죄 데이터에 대해서 분석을 해보고 시각화 해보도록 하겠습니다.
먼저 Pandas를 이용해서 데이터를 불러옵니다.

범죄 종류 및 설명 , 무슨 요일인지 언제 일어났는지 지역은 언제인지 등등 범죄 사건에 대한 여러 데이터가 있는 것을 확인할 수 있습니다.
이번 Part1에 대해서는 위치를 제외한 다른 속성들에 대해서 분석해보도록 하고 Part2에서는 GeoPandas를 이용해서 위치 정보에 대해서 분석해보도록 하겠습니다.
이제 데이터 갯수와 Null 데이터를 체크해보도록 하겠습니다.

데이터 갯수가 총 150500개 인 것을 확인할 수 있습니다.
먼저 상위 10개의 범죄 종류 확인해보겠습니다.
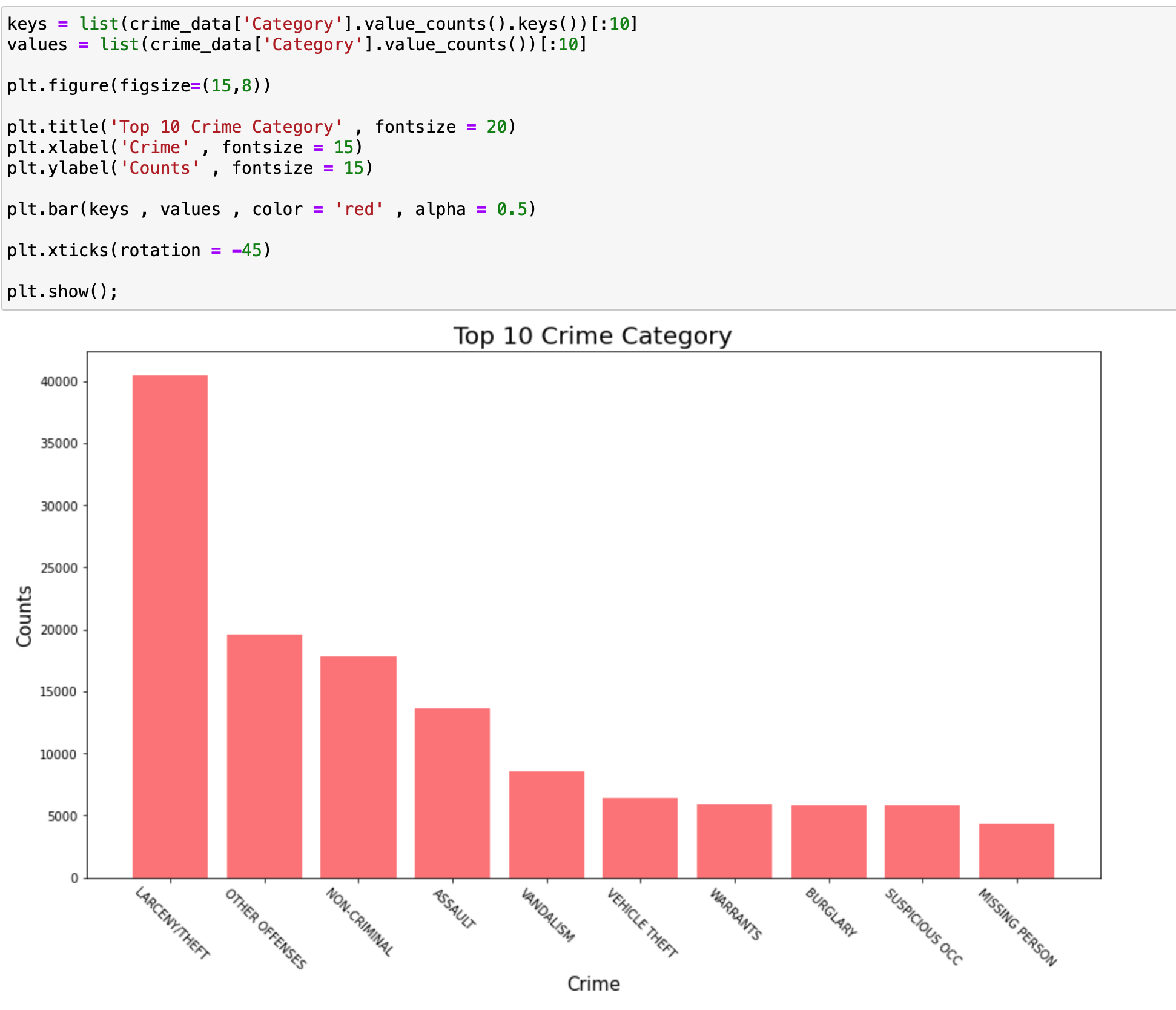
LARCENY/THEFT 항목 , 즉 절도 및 강도 죄가 가장 4만개로 가장 많은 것을 확인할 수 있습니다.
이제 요일에 대해서 분석해보도록 하겠습니다.

금요일과 토요일에 범죄가 다른 요일보다 더 많은 것을 확인할 수 있습니다.
다음은 Date에 대해서 분석해보도록 하겠습니다.
먼저 Date와 해당 Date에 일어난 범죄 수를 Dictionary 자료구조에 저장하도록 하겠습니다.

이제 여기서 날짜 별로 순서를 조정하기 위해서 Dictionary의 Key별로 정렬하도록 하겠습니다.

이제 이를 그래프로 그려보겠습니다.
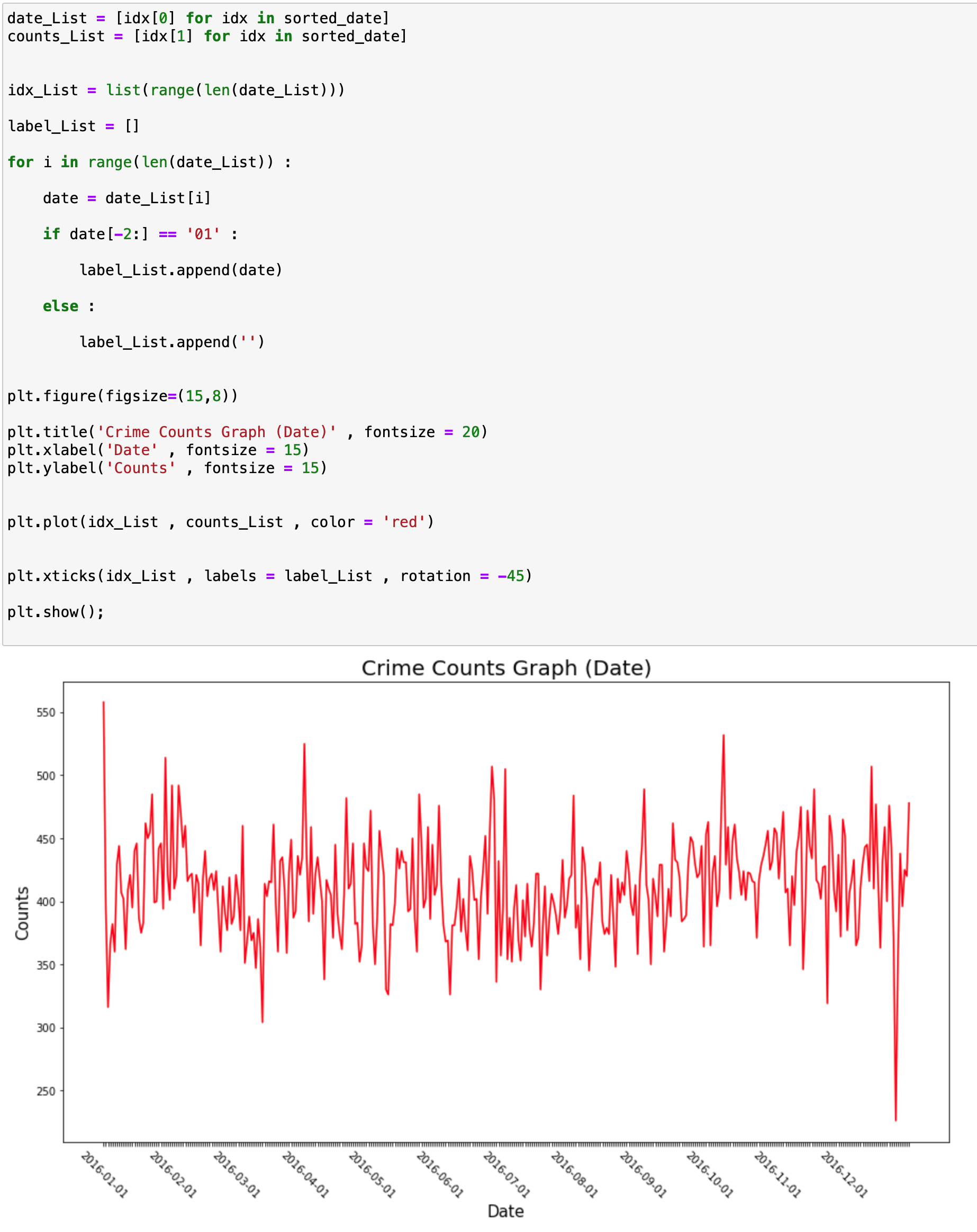
제 개인적으로 보기에는 Date와 범죄와는 크게 연관성을 파악하기가 힘든 것 같습니다.
이제 각 시간대별로 범죄 수와 연관지어서 확인해보곘습니다.

분 까지 확인하면 종류가 너무 많기 때문에 시 만을 추출해서 갯 수를 세보도록 하겠습니다.
아래는 이를 이용해서 만든 Bar Graph입니다.

보면 새벽에 범죄의 수가 다른 시간대에 비해서 매우 적음을 확인할 수 있으며 18~20시 사이에 범죄의 수가 가장 많이 일어나는 것을 확인할 수 있습니다.
이제 지역에 따라서 범죄의 수를 관련지어 보도록 하겠습니다.
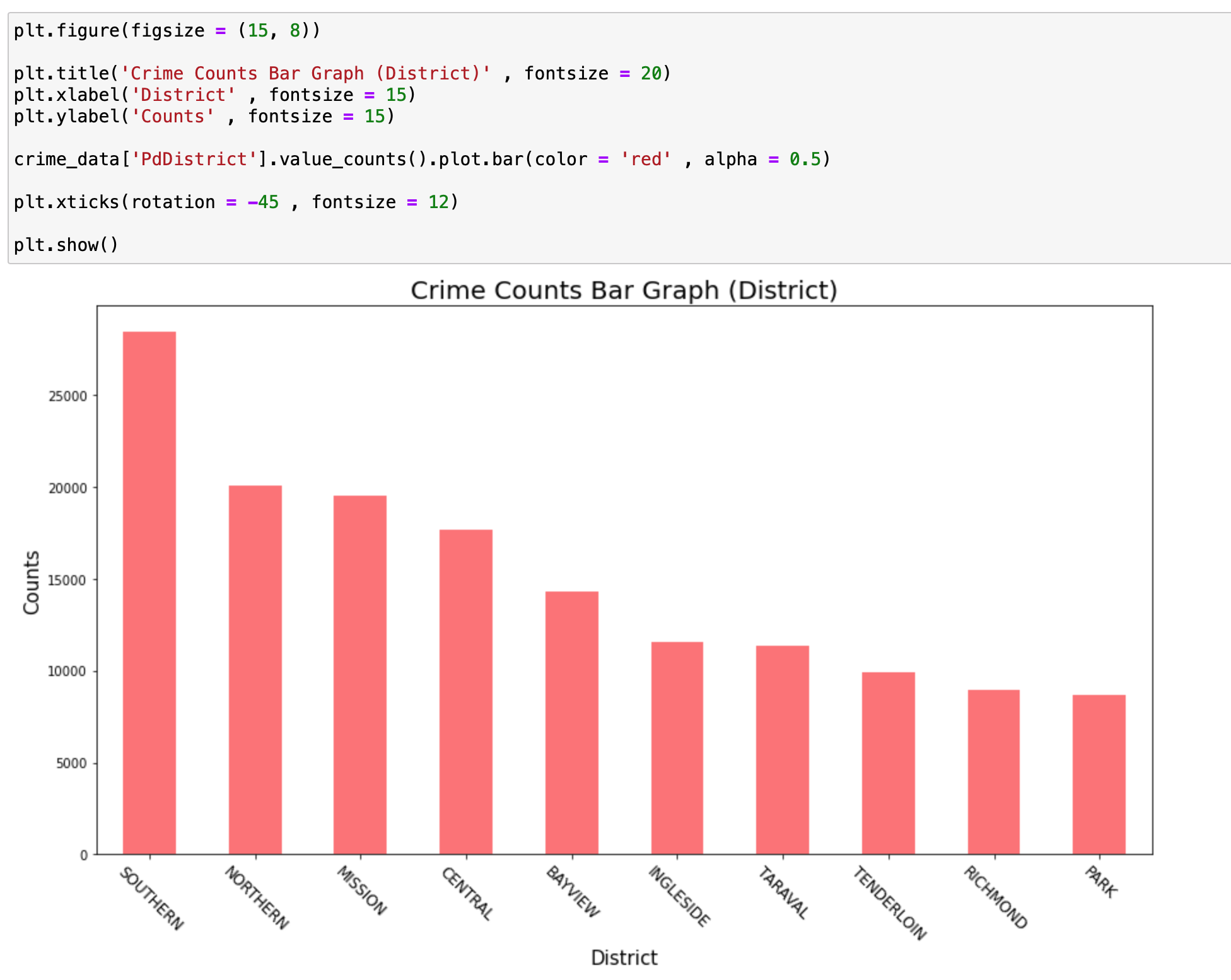
SOUTHERN 즉 남부 지역의 범죄 수가 가장 많이 일어나는 것을 확인할 수 있습니다.
이로써 샌프란시스코의 범죄 데이터 분석을 마쳐보도록 하겠습니다.
다음 포스팅에서는 위치 정보를 GeoPandas를 이용해서 데이터 분석을 해보도록 하겠습니다.
'Data Visualization' 카테고리의 다른 글
| DataVisualization - Seaborn 을 이용해서 스타벅스 설문조사 데이터 시각화하기 (0) | 2020.10.26 |
|---|---|
| Data Visualization - GeoPandas 이용해서 샌프란시스코 범죄 데이터 시각화하기 Part2 (0) | 2020.10.20 |
| Data Visualization - Corona Case를 Matplotlib animation으로 그래프 그리기 (0) | 2020.10.10 |
| Data Visualization - US Corona 분석하기 Part2 (0) | 2020.10.10 |
| Data Visualization - US Election Day Tweets 데이터 분석 Part1 (0) | 2020.10.07 |