데이터 출처 : www.kaggle.com/tongpython/cat-and-dog
Cat and Dog
Cats and Dogs dataset to train a DL model
www.kaggle.com
github 주소 : github.com/sangHa0411/DataScience/blob/main/CNN_Example.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
이번 포스팅에서는 CNN을 설계하는 과정을 정리해보도록 하겠습니다.
대표적인 이미지 분류 문제로 여겨지는 Cats and Dogs 문제를 다루어보겠습니다.
먼저 opencv 라이브러리를 이용해서 이미지 파일을 불러옵니다.
training_path = './archive/training_set/training_set/'
test_path = './archive/test_set/test_set/'
paths = [training_path , test_path]
kinds = ['cat' , 'dog']
image_Data = []
for path in paths :
image_Set = []
for idx in kinds :
sub_Images = []
for i in range(0 , 5001) :
image_path = path + idx + 's/' + idx + '.' + str(i) + '.jpg'
image = cv2.imread(image_path)
if str(type(image)) == "<class 'numpy.ndarray'>" :
image = cv2.resize(image , (160 , 160) , interpolation=cv2.INTER_LINEAR)
image = cv2.cvtColor(image , cv2.COLOR_BGR2GRAY)
image = image.astype('float')
image /= 255
sub_Images.append(image)
image_Set.append(sub_Images)
image_Data.append(image_Set)
그리고 불러온 이미지를 한 장씩 불러와서 고양이 사진과 강아지 사진을 비교해보겠습니다.
image_List = image_Data[0]
example1 = image_List[0][0]
example2 = image_List[1][0]
plt.figure(figsize = (15 , 5))
plt.subplot(1,2,1)
plt.imshow(example1 , cmap = 'gray')
plt.subplot(1,2,2)
plt.imshow(example2 , cmap = 'gray')
plt.show()
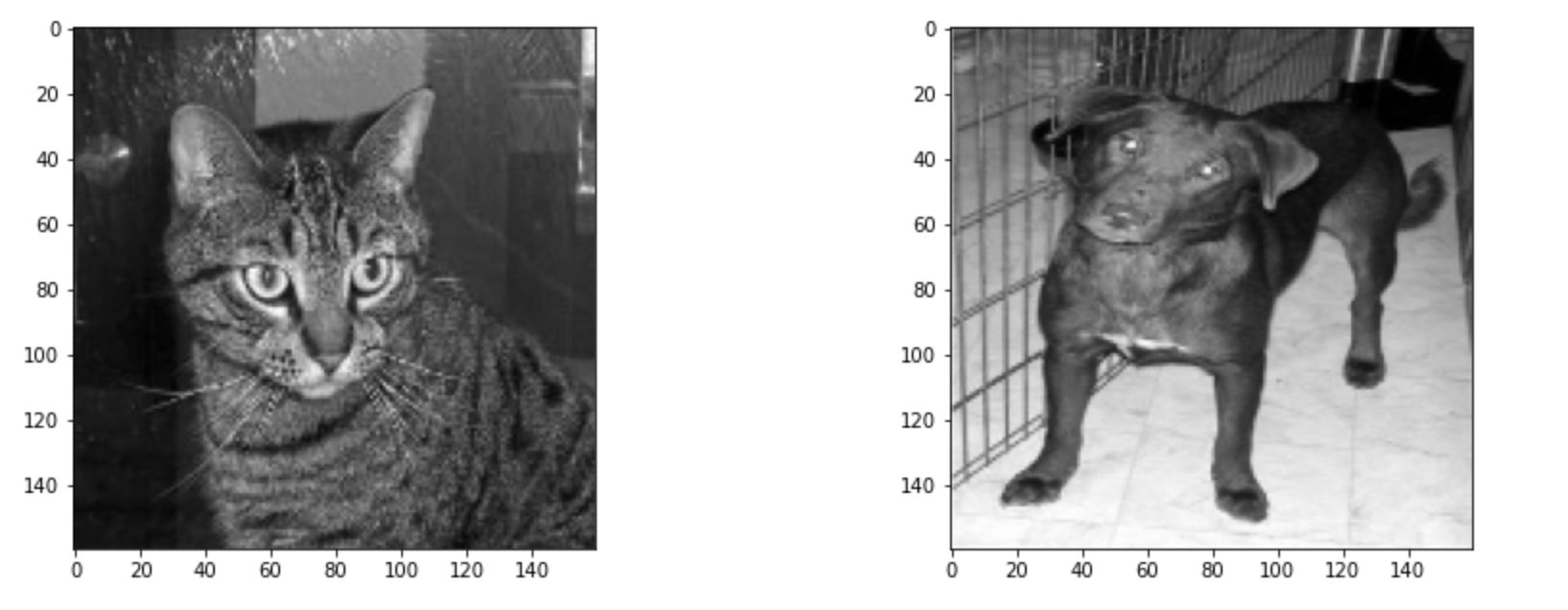
이제 불러온 이미지 데이터에서 훈련 데이터 그리고 테스트 데이터로 나누도록 하겠습니다.
def getData(image_Data) :
train = image_Data[0]
train_cat = train[0]
train_dog = train[1]
X_train = []
Y_train = []
train_Length = len(train_cat)
for i in range(train_Length) :
X_train.append(train_cat[i])
Y_train.append(0)
X_train.append(train_dog[i])
Y_train.append(1)
test = image_Data[1]
test_cat = test[0]
test_dog = test[1]
X_test = []
Y_test = []
test_Length = len(test_cat)
for i in range(test_Length) :
X_test.append(test_cat[i])
Y_test.append(0)
X_test.append(test_dog[i])
Y_test.append(1)
return np.array(X_train) , np.array(Y_train) , np.array(X_test) , np.array(Y_test)
X_train , Y_train , X_test , Y_test = getData(image_Data)
이진 분류 문제이므로 고양이는 0 , 강아지는 1로 레이블 값을 설정하였습니다.
다음으로 훈련 데이터와 테스트 데이터의 shape을 확인해보곘습니다.
print('train shape \n')
print(X_train.shape)
print(Y_train.shape)

총 8000장의 이미지가 있으며 한 장의 이미지의 높이 및 너비가 모두 160인 것을 확인할 수 있습니다.
여기서 주의할 점은 이 데이터를 CNN의 Convolution Layer로 입력하기 위해서는 지금의 shape으로 입력하면 안됩니다.
1개의 데이터가 지금은 2D tensor인 상황인데 여기서 3D tensor로 변경을 해주어야 합니다.
따라서 아래와 같은 과정이 꼭 필요합니다.
X_train = X_train.reshape(8000 , 160 , 160 , 1)
위와 같은 과정을 테스트 데이터에 동일하게 진행합니다.
X_test = X_test.reshape(2000 , 160 , 160 , 1)
이제 본격적으로 Keras를 이용해서 CNN을 설계해보겠습니다.
먼저 CNN을 위해 필요한 라이브러리를 가져오겠습니다.
from keras.models import Sequential , load_model
from keras.layers import Conv2D, MaxPooling2D , BatchNormalization, Dropout , Activation , Flatten, Dense
from keras.callbacks import EarlyStopping, ModelCheckpoint
그리고 이를 이용해서 CNN을 설계하겠습니다.
Sequential() 함수를 이용해서 model을 만든다음에 먼저 Convolution Layer와 Pooling Layer를 추가해줍니다.
model = Sequential()
# first Convolution Layer
model.add(Conv2D(input_shape = (160, 160, 1),
filters = 32,
kernel_size = (3,3),
strides = (1,1),
padding = 'same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# first Pooling Layer
model.add(MaxPooling2D(pool_size = (2,2)))
# second Convolution Layer
model.add(Conv2D(filters = 32,
kernel_size = (3,3),
strides = (1,1),
padding = 'same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# second Pooling Layer
model.add(MaxPooling2D(pool_size = (2,2)))
# third Convolution Layer
model.add(Conv2D(filters = 16,
kernel_size = (3,3),
strides = (1,1),
padding = 'same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Activation('relu'))
# third Pooling Layer
model.add(MaxPooling2D(pool_size = (2,2)))
그리고 나서 이를 평탄화해주어서 3D tensor를 1D tensor로 변경해줍니다.
model.add(Flatten())
이제 여기서 Fully Connected Layer를 추가해주는데 이진 분류이므로 마지막의 활성화 함수는 Sigmoid 함수로 설정합니다.
model.add(Dense(512 , activation='relu' , kernel_initializer = 'he_normal'))
model.add(Dropout(0.5))
model.add(Dense(1 , activation='sigmoid'))
model.compile(loss='binary_crossentropy' , optimizer='adam' , metrics=['acc'])
이제 훈련할 때 설정할 옵션을 정해줍니다.
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=5)
mc = ModelCheckpoint('best_model.h5', monitor='val_loss', mode='min', verbose=1, save_best_only=True)
EarlyStopping 으로 Validation loss 가 5회 이상 개선되지(감소되지) 않으면 훈련을 중지합니다.
그리고 ModelCheckpoint 함수를 이용해서 가장 작은 Validation loss 를 가질 때의 모델을 best_model.h5 로 저장합니다.
이제 최종적으로 모델을 훈련합니다.
history = model.fit(X_train, Y_train, \
epochs = 30, \
callbacks = [es, mc], \
batch_size = 128, \
validation_split = 0.2 )
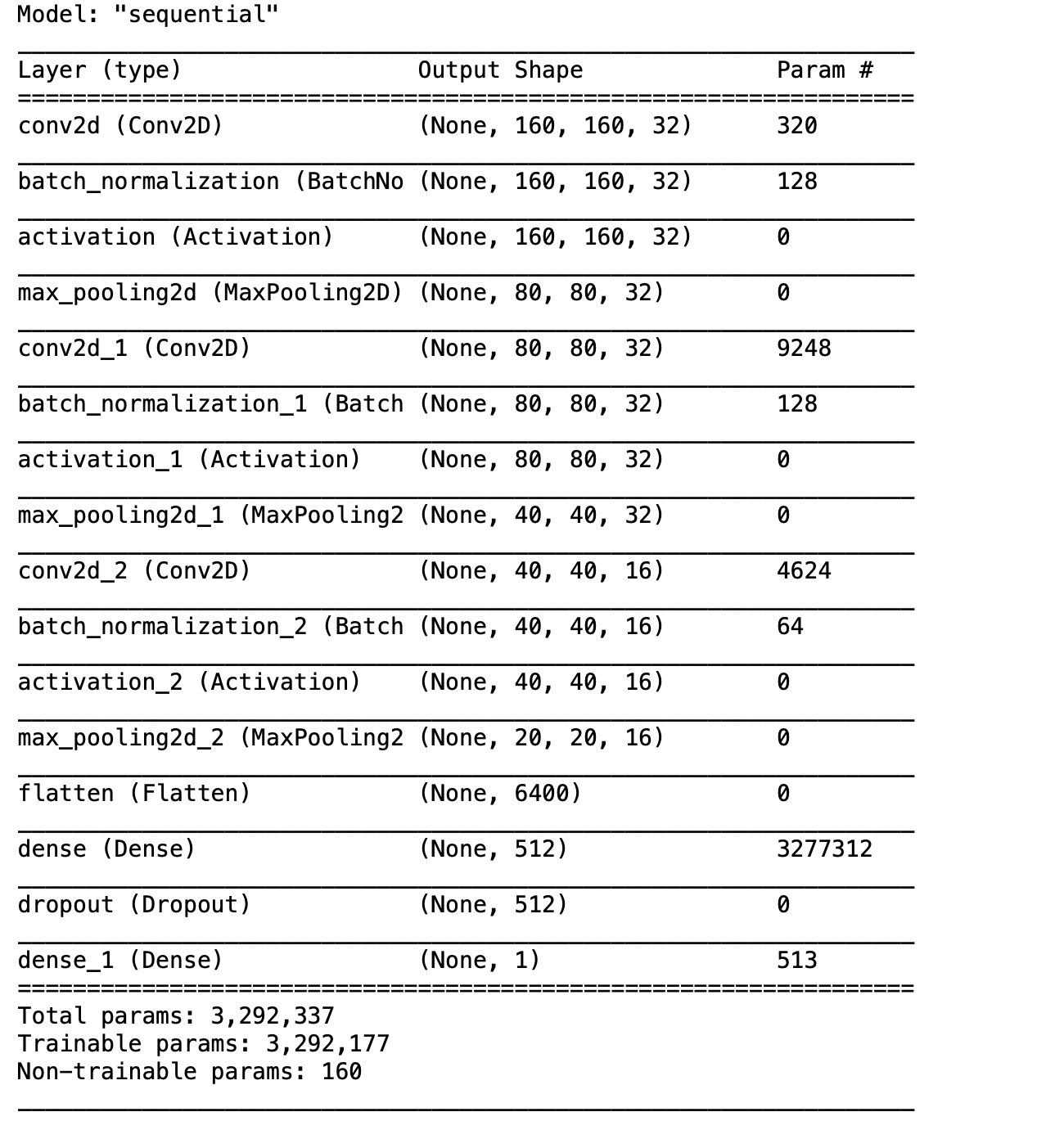
아래는 전체적인 모델의 내용입니다.
model.summary()
이제 학습 과정을 그래프로 그려보겠습니다.
fig , axes = plt.subplots(1 , 2 , figsize=(15,5))
axes[0].set_title('model accuracy')
axes[0].plot(history.history['acc'] )
axes[0].plot(history.history['val_acc'])
axes[0].set_ylabel('accuracy')
axes[0].set_xlabel('epoch')
axes[0].legend(['train', 'val'], loc='upper left' , fontsize=15)
axes[1].set_title('model loss')
axes[1].plot(history.history['loss'])
axes[1].plot(history.history['val_loss'])
axes[1].set_ylabel('loss')
axes[1].set_xlabel('epoch')
axes[1].legend(['train', 'val'], loc='upper right' , fontsize=15)
plt.show()

최종적으로 테스트 데이터를 이용해서 모델을 평가해보겠습니다.
loaded_model = load_model('best_model.h5')
result = loaded_model.evaluate(X_test, Y_test)
print('')
print("Test Loss : %.4f" % result[0])
print("Test Accuracy : %.4f" % result[1])

참고자료 : www.yes24.com/Product/Goods/65050162
케라스 창시자에게 배우는 딥러닝
단어 하나, 코드 한 줄 버릴 것이 없다!창시자의 철학까지 담은 딥러닝 입문서케라스 창시자이자 구글 딥러닝 연구원인 저자는 ‘인공 지능의 민주화’를 강조한다. 이 책 역시 많은 사람에게
www.yes24.com
'Deep Learning' 카테고리의 다른 글
| Deep Learning - 딥러닝의 활성화 히트맵 시각화하기 (0) | 2020.11.08 |
|---|---|
| Deep Learning - CNN을 이용한 Face Expression 파악하기 Part2 (0) | 2020.10.20 |
| Deep Learning - CNN을 이용한 Face Expression 파악하기 Part1 (0) | 2020.10.19 |
| Deep Learning - Corona Tweets 분석하기 Part3 : 트위터 감정 분석하는 LSTM 기반 모델 만들기 (0) | 2020.10.19 |
| Deep Learning - Corona Tweets 분석하기 Part2 : 텍스트 전처리하기 (0) | 2020.10.19 |