데이터 출처 : www.kaggle.com/lodetomasi1995/income-classification
Income classification
Prediction task is to determine whether a person makes over 50K a year.
www.kaggle.com
Ipynb File : github.com/sangHa0411/DataScience/blob/main/Income_Prediction_Part1.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
Part1 에서는 위 Kaggle 데이터를 분석 및 시각화 해보겠습니다.
Part2 에서는 Part1에서 분석한 결과에 기반해서 데이터를 전처리하고 Machine Learning의 Logistic Regression 알고리즘의 원리를 알아보겠습니다.
Part3 에서는 Scikit Learn에서의 Logistic Regression 사용방법을 살펴보겠습니다.
먼저 데이터의 csv파일로 된 데이터를 pandas를 이용해서 불러오고 데이터 구조를 파악해봅니다.

target Data는 income 데이터가 되는 것을 확인할 수 있습니다.
그리고 나머지 속성은 데이터 분석을 통해서 income과 상관이 있는지 없는 지를 파악해보는 것이 이번 포스팅의 목표입니다.
먼저 데이터 income Data의 클래스 및 갯수를 파악 및 비교해보겠습니다.

위 분석 결과를 통해서 Income 속성의 클래스는 총 2개 50k 가 넘는가 넘지 못하는가 가 되는 것을 알 수 있다. 그리고 50k 넘지 못하는 데이터 갯수가 25000개 그리고 넘는 데이터 갯수가 7000정도로 비율로 따지면 가각 76%. , 24%가 되는 것을 확인할 수 있다.
Income과 Sex와 연관지어서 데이터를 분석해보면 아래와 같다.

비율로 따지자면 남성의 경우 income이 50k가 넘는 경우가 대략 50%정도 되는 것을 알 수 있다, 그에 비해 여성의 경우 income이 50k가 넘는 비율이 10%정도로 매우 작다는 것을 알 수 있다. 따라서 데이터 상으로는 성별이 income에 영향을 많이 준다는 것을 파악 가능하다.
Income 과 workclass와 연관지어서 분석해보겠습니다.

분석 결과 income 50k가 넘는 데이터의 대부분이 private에 속하는 것을 확인할 수 있습니다. 그리고 유일하게 수입이 50k가 넘는 비율이 더 높은 workclass는 self emp inc 인 것을 확인할 수 있습니다.
Income 과 Occupation 즉 직업과 연결해서 분석해보겠습니다.

분석 결과를 보시면 Exec - managerial 그리고 prof-speciality에서의 수입이 50k가 넘는 데이터의 비율이 상당히 높은 것을 확인할 수 있고 나머지는 수입이 50k 넘는 데이터 그리고 넘지 못하는 비율의 격차가 큰 것을 확인할 수 있습니다.
Income과 education 즉 교육 정도를 연관지어서 분석해보겠습니다.

수입이 50k가 넘는 데이터의 수가 수입이 50k을 넘지 안되는 데이터의 수보가 큰 education 항목은 master , doctorate 즉 박사과정과 같은 경우인 것을 확인할 수 있습니다. 그리도 데체적으로 교육 과정이 길수록 수입이 50k 넘는 데이터의 수의 비율이 더 큰 것을 확인할 수 있습니다.
이제 Income과 Race 즉 인종과 연관지어서 분석해보곘습니다.

White의 데이터가 압도적으로 많은 것을 확인할 수 있습니다. 수입이 50k가 넘는 데이터가 대략 8000인데 그 중에서 7500가량의 인종이 백인이므로 인종 또한 어느정도 Income에 영향을 미친다고 할 수 있을 것 같습니다.
이제 Income 과 국가를 비교해보겠습니다.
데이터 상에서의 국가들의 수는 대략 50개 정도로 매우 많지만 데이터 상에서 국가가 US인 데이터가 매우 많고 나머지는 매우 적기 떄문에 편의상 US와 그 외 나머지로 이분해서 분석하였습니다.
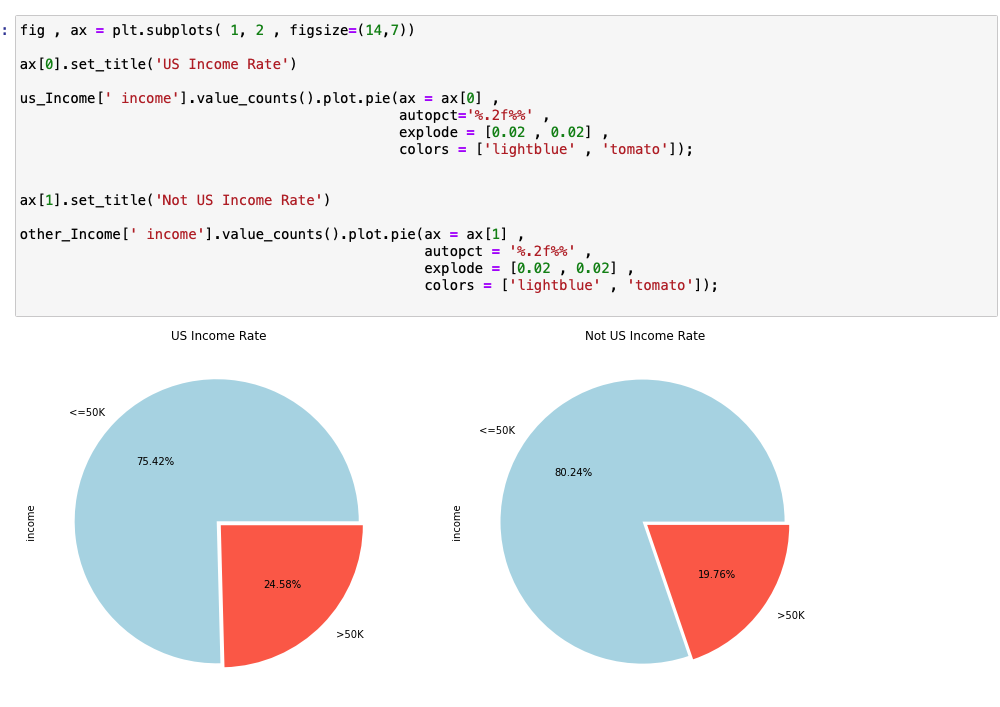
2 클래스의 Income Class의 비율이 비슷한 것을 확인할 수 있었습니다.
이제 어느 정도 데이터 분석을 마쳤으니 이제 최종적으로 Income과 다른 Column의 상관 관계를 분석해서 최종적으로 Logistic Regression 에 어떠한 속성을 사용할지에 대해서 결정하도록 하겠습니다.
먼저 데이터를 0 , 1 로 인코딩합니다
1은 Income이 50k가 넘는 것을 의미하고
0은 Income이 50k가 넘지 못하는 것을 의미합니다.

이제 상관관계 행렬을 만들어서 각 속성들이 서로 얼마나 관계있는지 파악합니다.
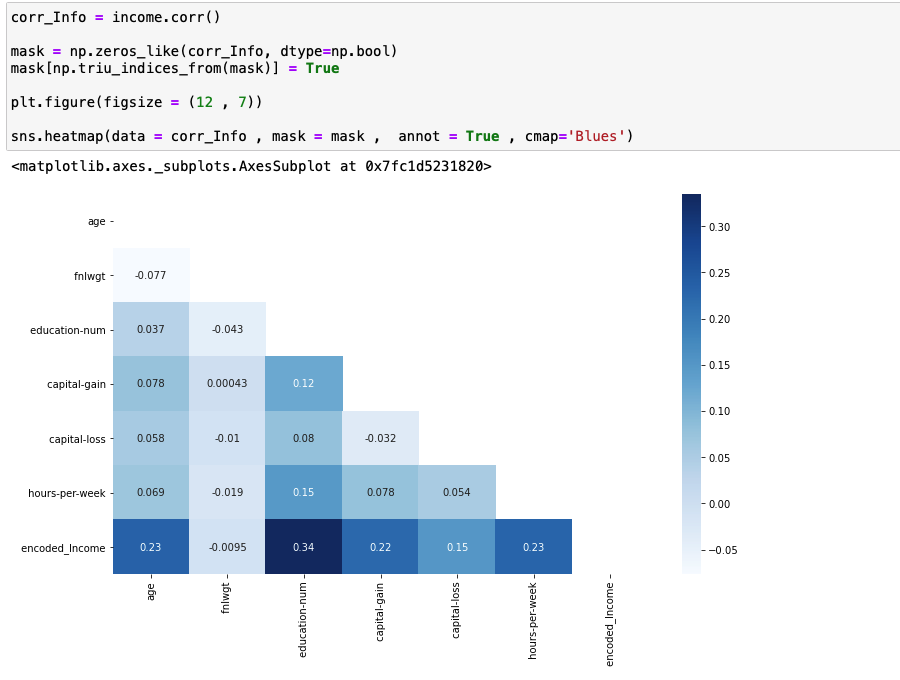
이 중에서 Income과 다른 속성들과의 관계를 구체적으로 수치로 파악하고자 합니다.
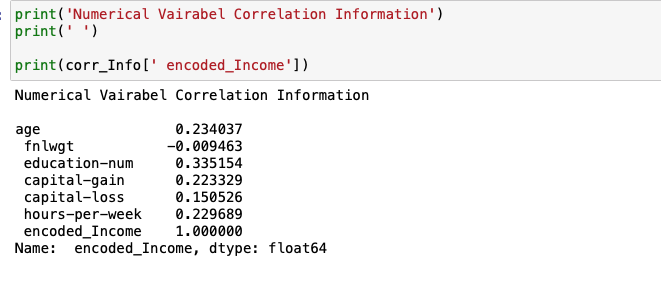
수치를 살펴본 결과 fnlwgt는 Income과 상관이 거의 없다라는 것을 확인할 수 있습니다.
이로써 저희는 연속적인 속성은 상관관계 행렬을 통해서 Income과의 연관성을 파악하였고 이산적인 속성은 주로 pie chart 와 bar chart를 이용해서 income과의 상관관계를 분석해보았습니다.
Part2에서는 위 결과를 기반으로 해서 데이터를 전처리해서 Logistic Regression을 구현 및 분석해보겠습니다
'Machine Learning' 카테고리의 다른 글
| Machine Learning - Logistic Regression 연봉 예측하기 Part3 (0) | 2020.10.05 |
|---|---|
| Machine Learning - Logistic Regression 연봉 예측하기 Part2 (0) | 2020.10.05 |
| MachineLearning - Decision Tree 타이타닉 생존자 예측하기 Part3 (0) | 2020.10.05 |
| MachineLearning - Decision Tree 타이타닉 생존자 예측하기 Part2 (0) | 2020.10.05 |
| MachineLearning - Decision Tree 타이타닉 생존자 예측하기 Part1 (0) | 2020.10.05 |