데이터 출처 : www.kaggle.com/mustafaali96/weight-height
weight-height.csv
weights and heights.
www.kaggle.com
github 주소 : github.com/sangHa0411/DataScience/blob/main/Statistics_Part1.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
이번 포스팅에서는 Python의 Scipy 라이브러리를 이용해서 모집단 및 표본에서의 통계량을 구하는 방법 및 모집단 및 표본의 통계량의 관계에 대해서 정리해보고자 합니다.
먼저 데이터에 관해서 말씀드리고자 합니다.
데이터의 구조는 다음과 같습니다.
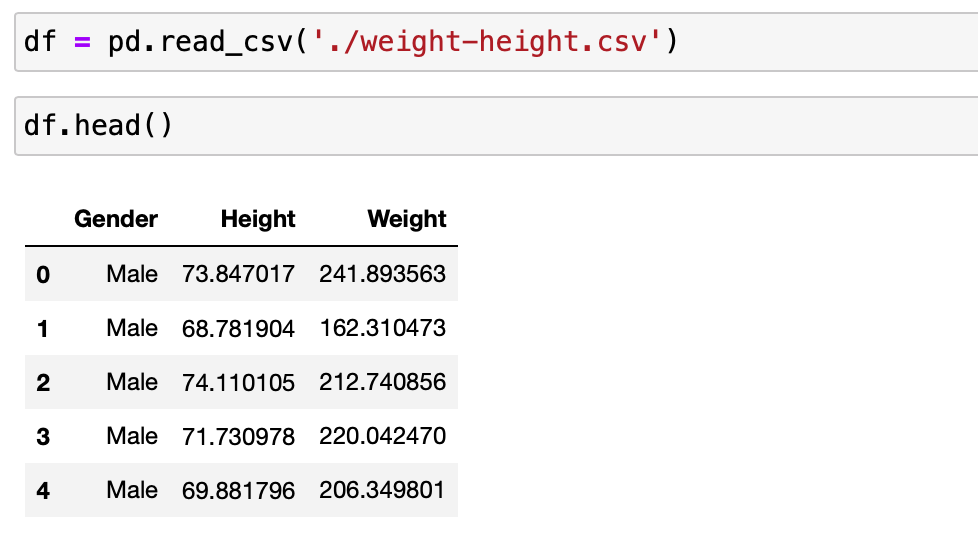
다변량 데이터를 다루는 방법을 정리하기 앞서서 먼저 1변량 데이터를 다루는 방법을 정리하기 위해서 남성의 키 데이터만을 뽑아서 다루어보도록 하겠습니다.
데이터를 추출하는 과정은 위 github 주소에 가시면 확인하실 수 있습니다.
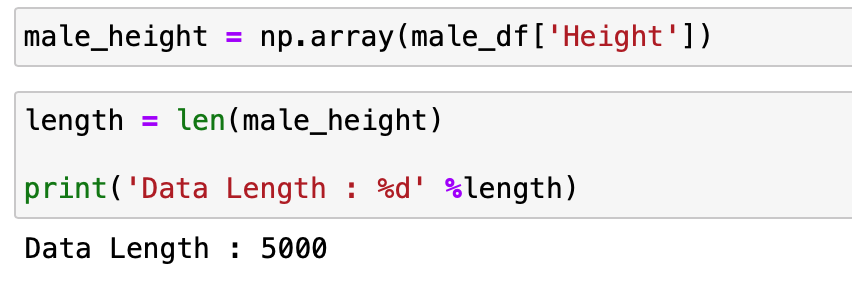
위 데이터는 1변량 데이터이기 때문에 scipy의 함수를 이용해서 평균 , 분산 및 표준편차 값을 바로바로 구할 수 있습니다.
통계량중 mean 즉 평균값(기댓값)의 식은 다음과 같습니다.
구하고자 하는 통계량은 다음과 같습니다.
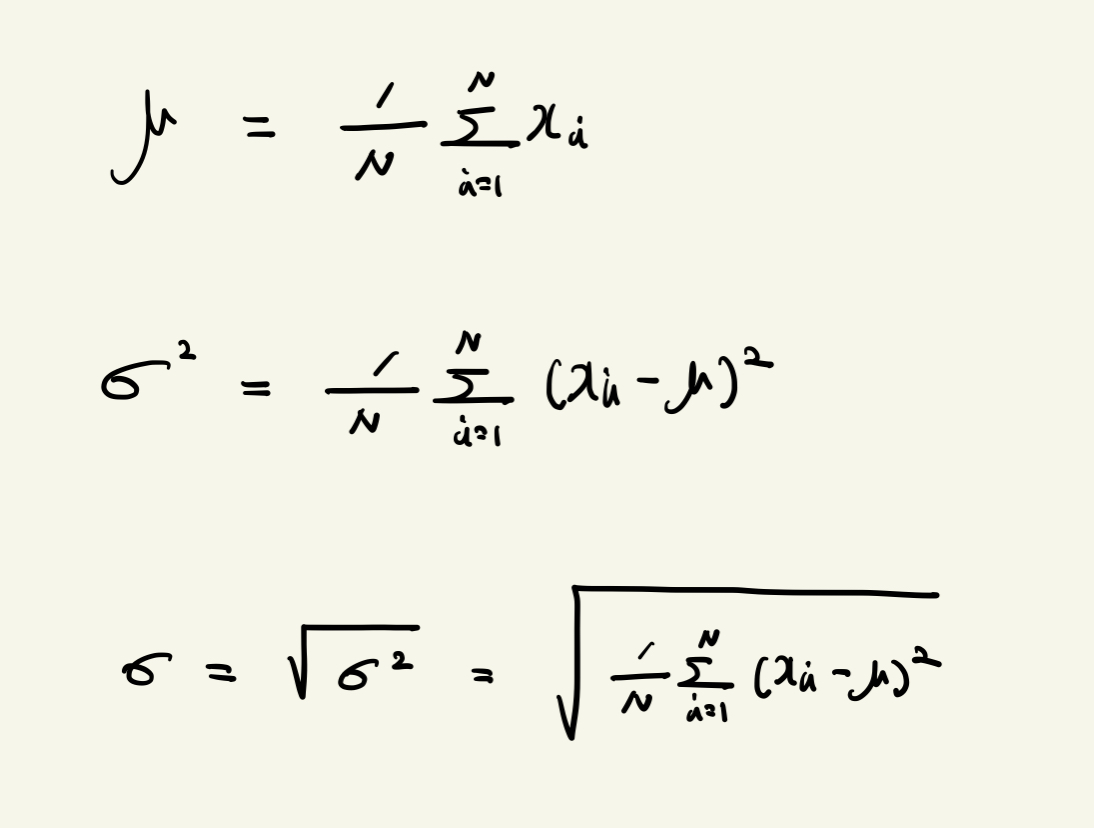
위에서 부터 평균값(기댓값) , 분산 그리고 표준편차입니다.
위의 통계량을 구하는 방법은 아래와 같습니다.

위 데이터를 모집단 데이터라고 생각하겠습니다.
다음으로 모집단 데이터의 히스토그램을 그려서 데이터 시각화를 해보겠습니다.

여기서 랜덤으로 사이즈가 200인 표본을 1개 추출해보겠습니다.

replace = False 로 설정하여서 비복원 추출을 하였습니다.
즉 같은 데이터를 2번 이상 추출하지 않는 것을 의미합니다.
이제 표본에 대해서 통계량을 구해보도록 하겠습니다.

표본에 대해서도 히스토그램을 그려서 모집단의 히스토그램과 비교해보도록 하겠습니다.
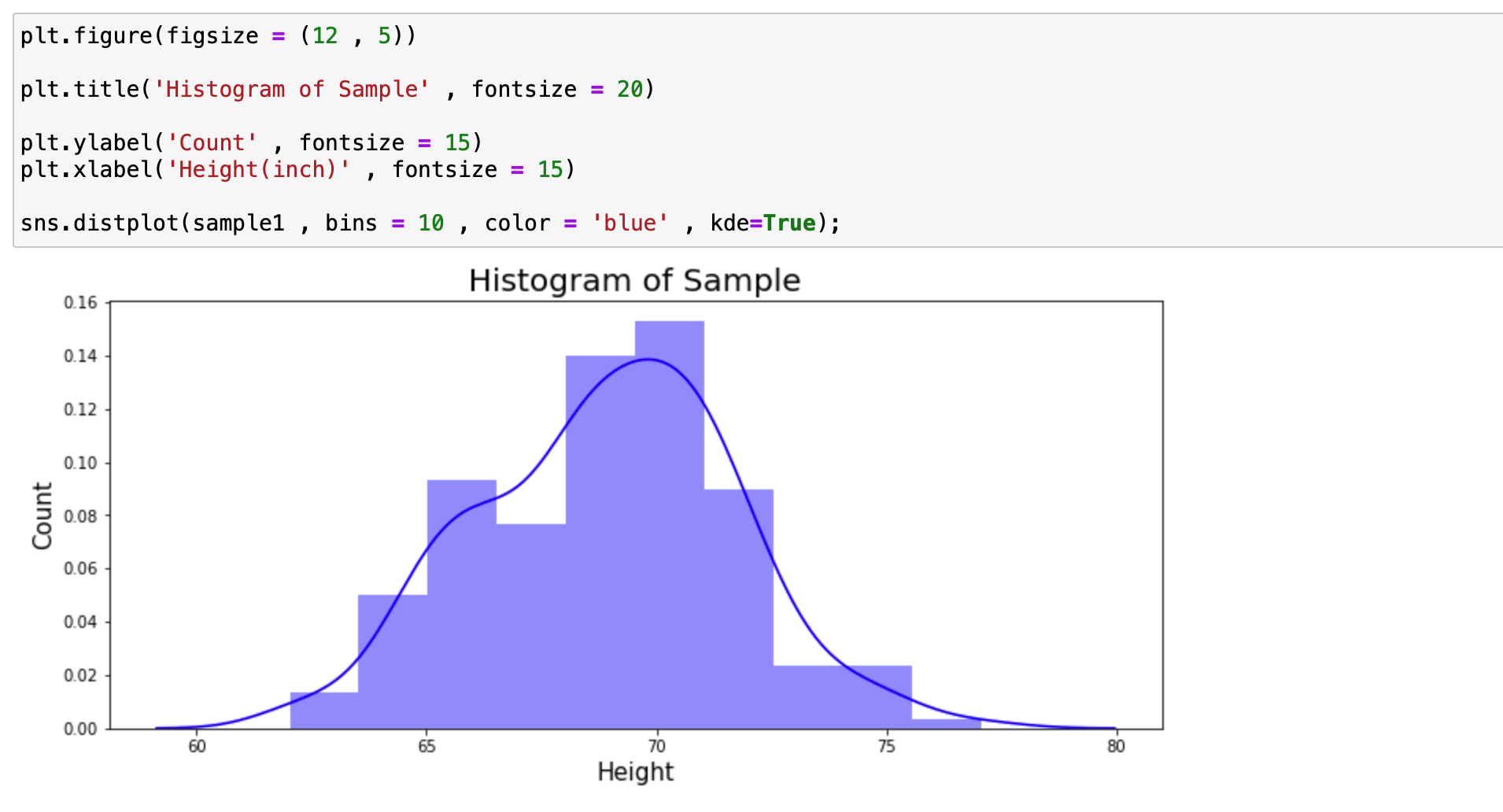
표본과 모집단의 히스토그램의 모양이 어느정도 비슷하다라는 것을 파악할 수 있습니다.
앞서 구한 통계량은 모집단에서 원소 200개를 추출해서 만든 1개의 표본에 대한 것입니다.
이제 저희는 같은 모집단에서 많은 표본을 구해보고 이를 이용해서 표본과 모집단의 통계량의 관계에 대해서 분석해보고자 합니다.
먼저 크기가 20인 표본을 200개를 추출합니다.

크기가 20인 표본을 추출하면서 각 표본의 평균값을 random_mean 리스트에 저장합니다.
즉 크기가 20인 표본들의 평균들이 저장된 리스트입니다.
여기서 무작위로 선정해서 표본 평균들의 평균들을 구해서 이와 모집단의 평균과 비교해보곘습니다.

1부터 200까지 random_mean에 있는 표본 평균들을 무작위로 추출해서 그 평균들의 평균을 구하고 sm_mean1 함수에 저장합니다.
이 리스트 데이터와 모집단의 평균을 비교해보도록 하겠습니다.

표본들의 갯수가 많으면 많을 수록 표본 평균들의 평균 값이 모집단의 평균에 근접하는 것을 확인할 수 있습니다.
같은 방식으로 진행하되 이번에는 표본의 크기를 20에서 100으로 늘려보겠습니다.

y축의 값이 크기가 200일 때는 주로 68.9 ~ 69.05에 위치하는 것을 확인하면서 크기가 20일 때 보다 더 적은 폭으로 근접하는 것을 확인할 수 있습니다.
이를 하나의 화면에 겹쳐 그려서 비교해보겠습니다.
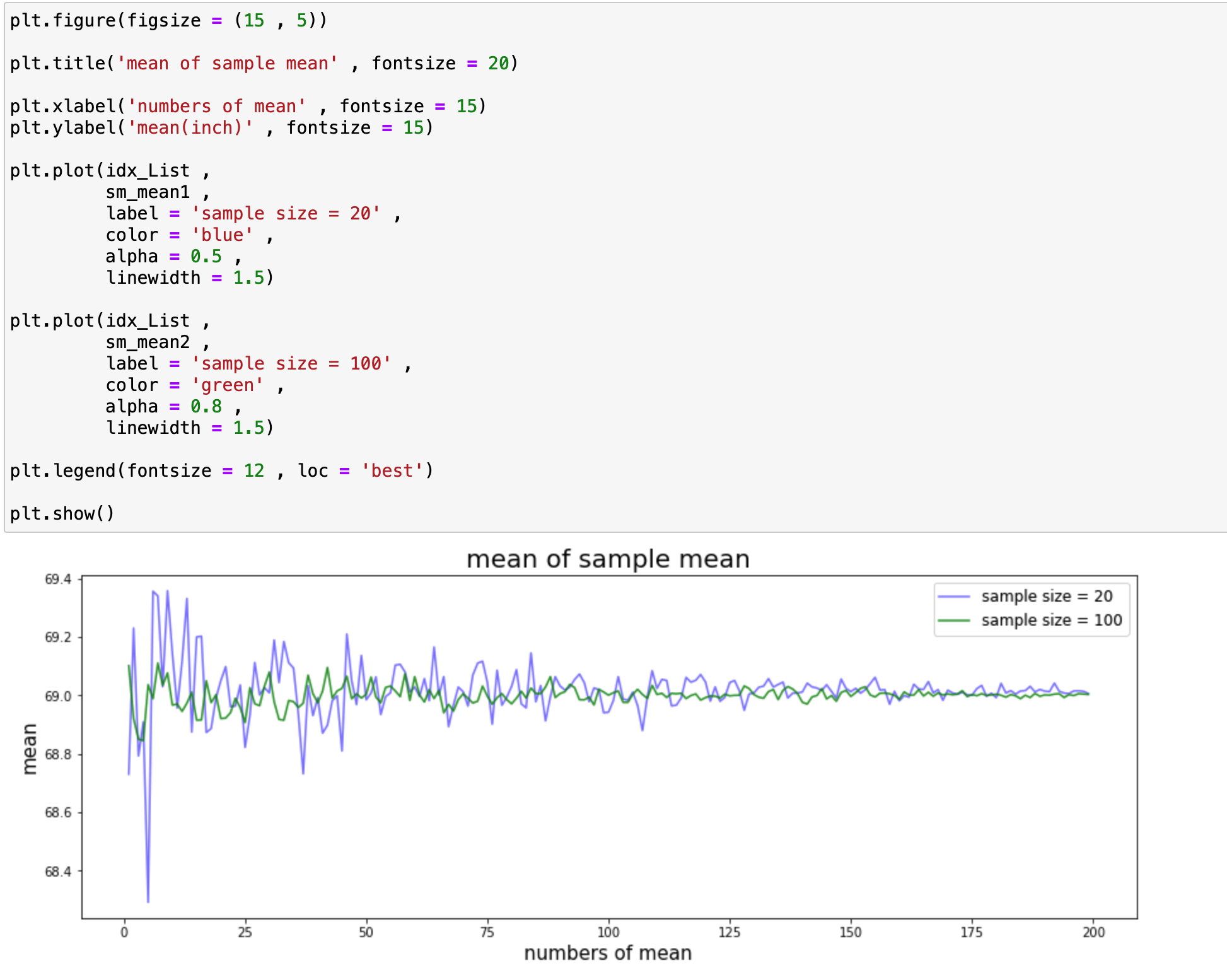
표본의 크기가 100인 표본들의 평균들로 평균을 구한 값이 훨씬 더 적은 폭을 가진다는 것을 확인할 수 있습니다.
즉 정리하자면 표본의 크기가 클 수록 표본 평균들의 평균 값은 모집단의 평균에 근접한다는 것을 확인할 수 있습니다.
이를 다른 방향으로 확인해보겠습니다.
먼저 표본의 크기를 점점 더 증가하면서 해당 크기의 표본을 갯수를 100개로 해서 표본 평균들의 평균들로 이루어진 데이터의 표준편차를 구해보겠습니다.

표본의 크기가 10 , 20. 30 점점 늘어나서 200개 까지 증가하는데 위 크기의 표본을 100개를 추출하고 그들의 평균들로 이루어진 리스트를 만듭니다. 그리고 그 리스트의 표준편차를 구해서 최종 random_std 리스트에 저장합니다.
이제 이 리스트를 이용해서 데이터를 시각화 해보겠습니다.

위 에서 확인할 수 있듯이 표본의 크기가 클 수록 표준 편차가 작아지는 것을 확인할 수 있습니다.
정리하자면 표본의 크기가 클 수록 표본의 평균들로 이루어진 평균은 모집단에 평균에 근접한다는 것을 확인할 수 있습니다.
참고자료 : www.yes24.com/Product/Goods/85743006
파이썬으로 배우는 통계학 교과서
이론이나 수식을 몰라도 파이썬 함수로 이해하는 통계학 데이터 분석에 관심이 높아지면서 통계학이 주목받고 있다. 이 책은 데이터 분석 관점에서 통계학을 설명한다. 어려운 통계학 개념을
www.yes24.com
'Statistics' 카테고리의 다른 글
| Statistics - Scipy를 이용한 통계적 가설 검정하기 (0) | 2020.11.01 |
|---|---|
| Statistics - Scipy 을 이용해서 표본 통계량 활용해 모수 추정하기 (0) | 2020.10.26 |