데이터 출처 : research.google/tools/datasets/google-facial-expression/
Google facial expression comparison dataset – Google Research
This dataset is a large-scale facial expression dataset consisting of face image triplets along with human annotations that specify which two faces in each triplet form the most similar pair in terms of facial expression. Each triplet in this dataset was a
research.google
github 주소 : github.com/sangHa0411/DataScience/blob/main/face_detection.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
이번 포스팅에서는 얼굴 사진 1000장과 얼굴이 없는 사진 1500장을 사용하고 Machine Learning에서 AdaBoost 기법을 사용해서 사진에서 얼굴 부분을 탐지해보도록 하겠습니다.
사진은 위 google의 face expression 데이터에서 가져왔으며 얼굴이 없는 사진 또한 위 사진에서 얼굴 부분을 제외한 부분을 추출함으로써 만들었습니다.
굳이 opencv의 라이브러리가 있는데도 직접 구현하면서 이번 포스팅에서 정리하는 이유는 얼굴 검출의 원리와 과정을 파악하기 위함입니다.
이를 하는 이유는 원리를 정확하게 안다면 추후에 얼굴 검출이 아니여도 다른 것을 검출할 때도 이러한 원리를 이용해서 검출을 할 수 있겠다 라고 생각해서입니다.
이 모든 과정은 아래의 참고자료에서 기반을 두어서 진행하였습니다.
참고자료 : towardsdatascience.com/a-guide-to-face-detection-in-python-3eab0f6b9fc1
A guide to Face Detection in Python
In this tutorial, we’ll see how to create and launch a face detection algorithm in Python using OpenCV and Dlib. We’ll also add some…
towardsdatascience.com
그럼 시작해보도록 하겠습니다.
먼저 얼굴 사진을 불러옵니다.
여기서 기존의 얼굴 검출을 원리를 다룬 자료를 보면 아래와 같은 사진에서 Haar Features라 하는 특징을 얼굴 사진의 여러 부분에서 추출합니다.

위와 같은 Harr Features들이 24 * 24 window에서 16만개 이상이 추출된다고 합니다.
따라서 저 또한 위에서 불러온 사진을 24 * 24 로 변형하고 이 사진에서 Haar Features를 검출할려고 합니다.
위에서 리스트에 저장되어 있는 얼굴 사진들을 순차적으로, 흑백으로 변경한 뒤에 크기를 (24 , 24) 로 변경해서 따로 저장합니다.
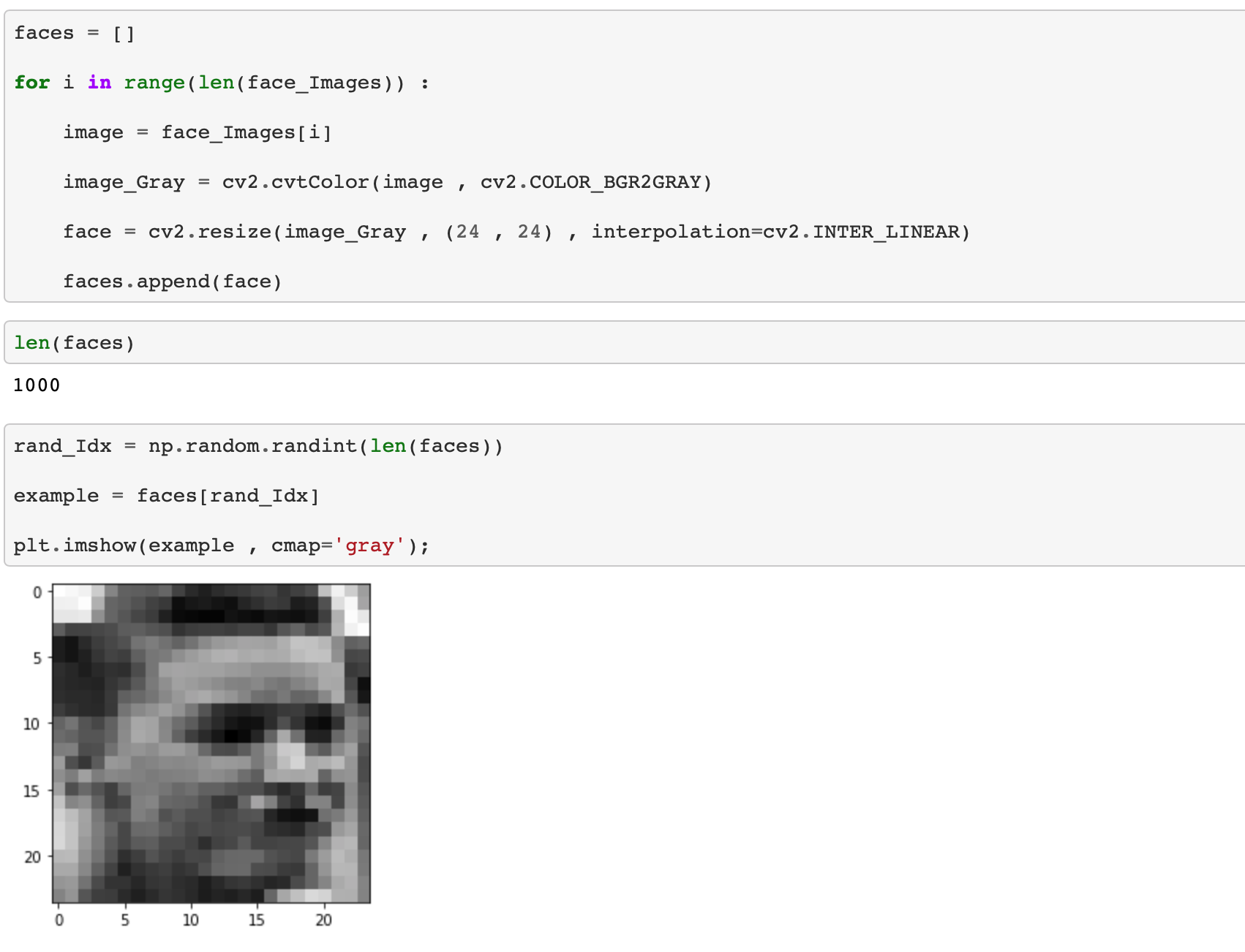
원래 사진이 크기가 (24, 24) 로 줄어들면서 기존의 얼굴 사진에 깨짐 현상이 많아진 것을 확인할 수 있습니다.
이제 이 위 흑백의 크기가 (24 , 24) 사진에서 Haar Feature를 추출할려고합니다.
아래는 위 참고자료에서 가져온 사진으로써 앞으로 추출할 Haar Features의 종료 입니다.
높이 및 너비가 달라질 수 있지만 크게 이렇게 5종류로 나뉘고 검은색 부분의 면적의 합 - 하얀색 부분의 면적의 합 = 특징 값
을 계산함으로써 특징을 추출하게 됩니다.
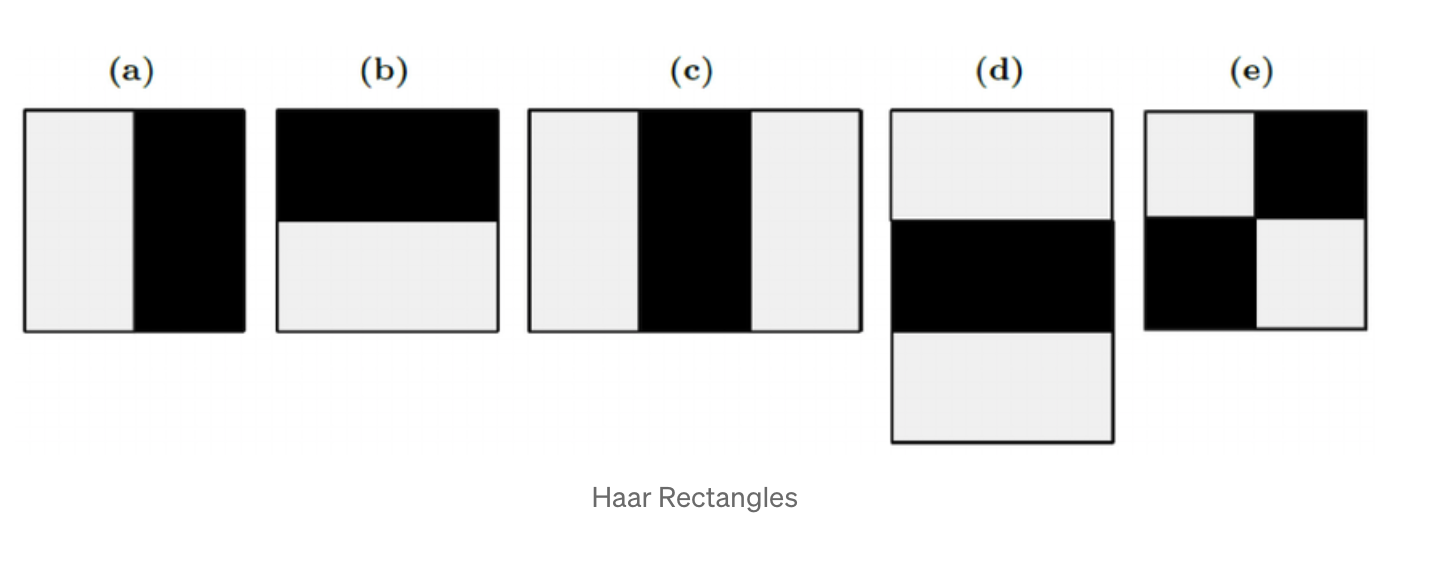
얼굴에서 추출한 엄청나게 많은 특징들 중에서 아래와 같은 위치에 (d) Haar Features와 같은 경우는 얼굴사진이냐 아니냐를 구분할 수 있는 중요한 특징이 됩니다. 이는 추후에 AdaBoost를 이용해서 선택할 것이며 먼저 이러한 특성을 추출하는 함수를 정의하도록 하겠습니다.

먼저 면적의 합을 편하게 계산하기 위해서 적분 영상을 구하는 함수를 정의합니다.

이렇게 적분영상을 구하는 이유는 아래에서 살펴볼 수 있습니다.
아래 사진 또한 위 참고자료에서 가져온 사진인데 이 사진이 적분 영상이라고 할 때 여기서 영역 D의 모든 픽셀의 합을 구할려면 4 + 1 - 2. - 3 으로써 구할 수 있기 때문입니다.
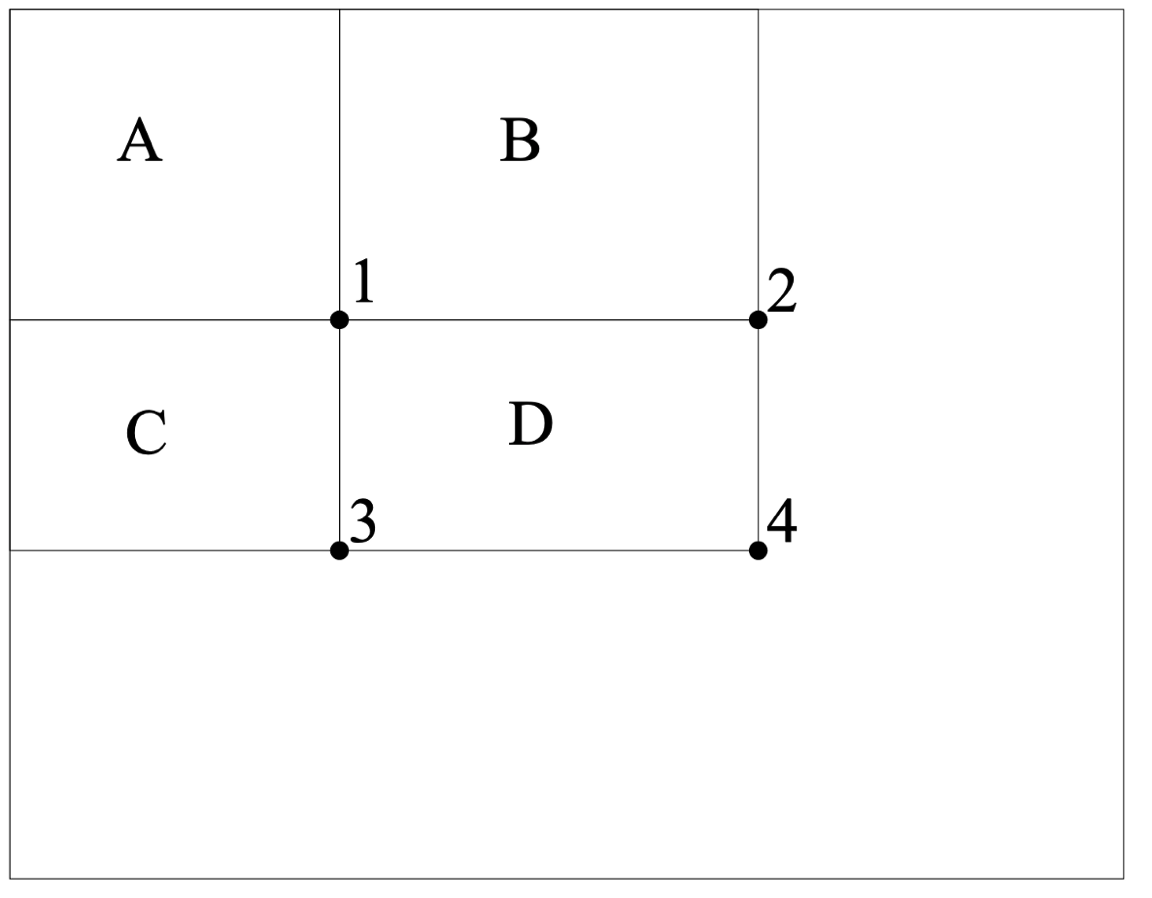
따라서 적분 영상을 이미 구하면 해당 적분 영상에서 3번의 덧셈 그리고 뻴셈으로 쉽게 면적에 있는 모든 픽셀의 합을 구할 수 있기 때문입니다.
아래는 위 적분 영상에서 Haar 특징들을 추출하는 함수입니다.
구체적으로는 위 github주소에 가시면 확인하실 수 있습니다.
보시면 (24 , 24) 사진에서 총 2만개의 특징을 추출한 것을 확인할 수 있습니다.
위 참고 자료 및 논문에서는 (24, 24) 사진에서 총 16만개가 넘는 특징을 추출할 수 있는데 굳이 2만개의 특징만을 추출하는 이유는 16만개가 넘는 특징을 모두 고려해서 AdaBoost기법을 이용하기에 제 컴퓨터의 속도가 너무 느려서입니다.
따라서 이번 포스팅에서는 2만개의 특징에서 계 중 얼굴이냐 아니냐를 가장 잘 구분할 수 있는 특징들을 AdaBoost로 선택하고 최종적으로 해당 특징들로 얼굴을 탐지해보도록 하겠습니다.
먼저 얼굴 사진 및 얼굴아 아닌 사진을 각각 나누어서 훈련 데이터 및 테스트 데이터에 저장합니다.

얼굴이면 1. , 얼굴이 아니면 0으로 label을 지정합니다.
이제 훈련 데이터 및 테스트 데이터를 전처리합니다.

데이터를 섞어주고 numpy array로 type을 변경한다음에 스케일을 255로 나눔으로써 픽셀의 값을 0~1 사이로 조정합니다.
근데 여기서 훈련 데이터 및 테스트 데이터는 사진으로 크기가 (24 ,24)인 이미지 데이터로 구성이 되어있으니 이 사진에서 Haar 특징을 뽑아주어야 합니다.


최종적인 훈련 데이터 및 테스트 데이터는 다음과 같습니다.

다음 part2에서는 위에서 추출한 Haar Features에서 AdaBoost를 이용해서 특성 선택을 하고 그 선택된 특성들을 이용해서 얼굴 검출을 해보도록 하겠습니다.
'Machine Learning' 카테고리의 다른 글
| Machine Learning - AdaBoost를 이용한 얼굴 검출하기 Part2 (0) | 2020.10.20 |
|---|---|
| Machine Learning - 주성분 분석과 Logistic Regression을 이용한 Credit Card Fraud 파악하기 (0) | 2020.10.19 |
| Machine Learning - Bayesian Linear Regression을 이용한 보험 비용 예측하기 Part2 (0) | 2020.10.11 |
| Machine Learning - Bayesian Linear Regression을 이용한 보험 비용 예측하기 Part1 (0) | 2020.10.10 |
| Machine Learning - Logistic Regression 심장 병 여부 예측하기 (0) | 2020.10.07 |