데이터 출처 : www.kaggle.com/datatattle/covid-19-nlp-text-classification
Coronavirus tweets NLP - Text Classification
Corona Virus Tagged Data
www.kaggle.com
github 주소 : github.com/sangHa0411/DataScience/blob/main/Corona_Tweets.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
이번 포스팅에서는 Corona와 관련된 tweet들에 대해서 텍스트 처리를 해보면서 데이터 분석을 해보도록 하겠습니다.
Part1 에서는 데이터 분석을 해보고
Part2에서는 Text 전처리 및 전처리된 Text를 Wordcloud으로 그려보겠습니다.
Part3에서는 Deep Learning을 이용해서 Tweet의 감정 분석을 해보도록 하겠습니다.
먼저 Pandas를 이용해서 데이터를 불러옵니다,

앞서 말씀드린대로 Part1 에서는 데이터 분석을 해보도록 하겠습니다.
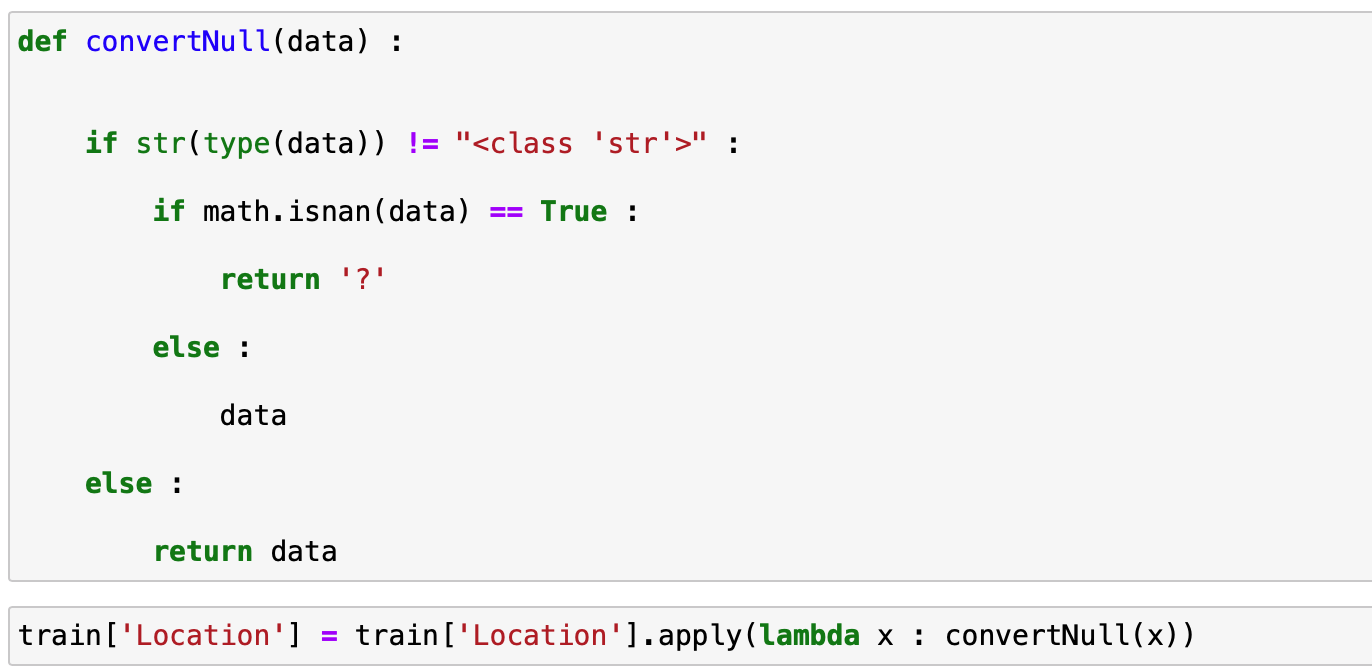
먼저 데이터에 있는 null 데이터를 체크해보록 하겠습니다.

여기서 Location 데이터에는 Null데이터가 총 8590개 있는데 이를 Null 데이터를 '?' 로 변경하도록 하겠습니다.
먼저 데이터 Column에서 Sentiment를 먼저 분석해보돍 하겠습니다.
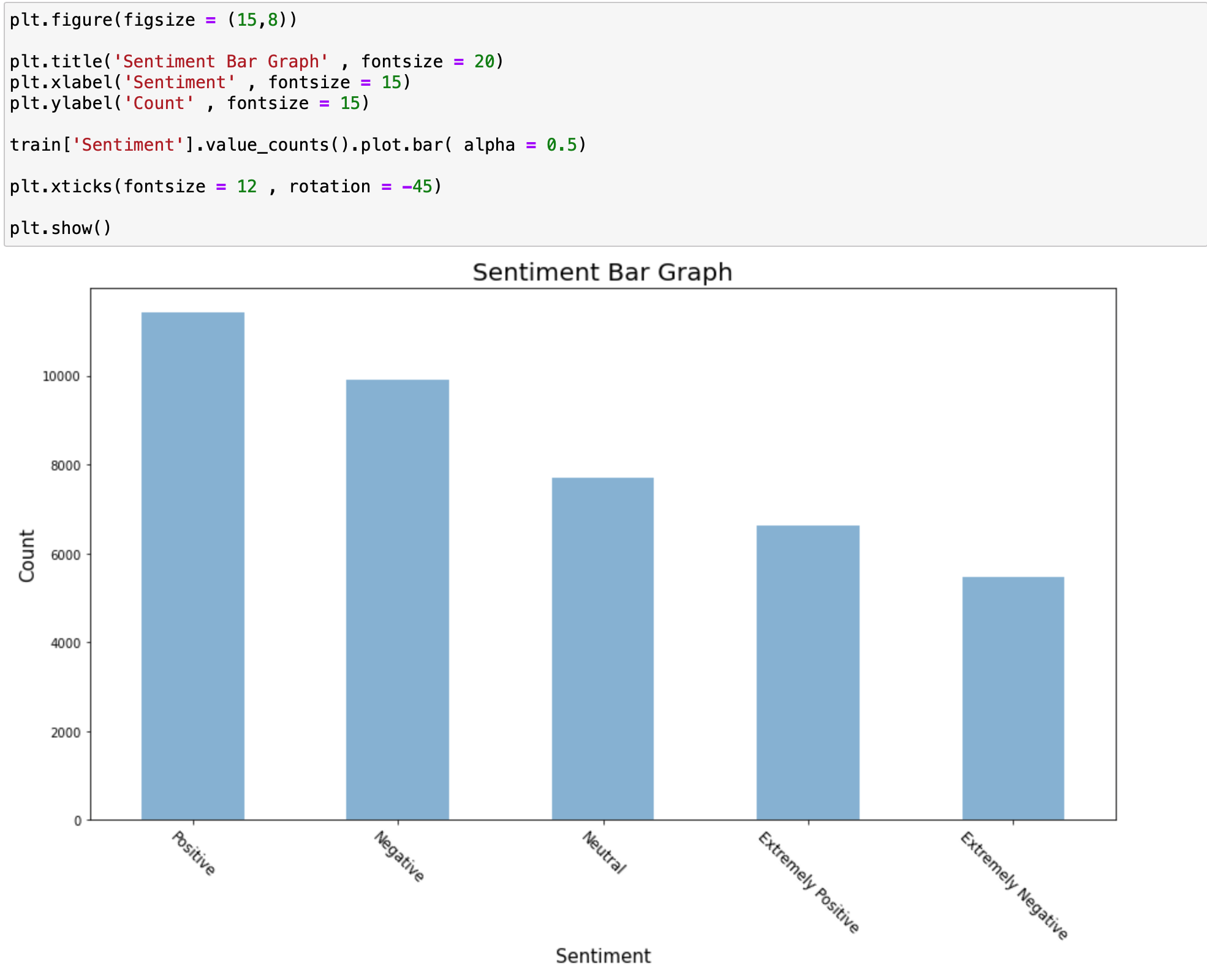
먼저 긍정과 부정 데이터가 많은 것을 확인 할 수 있으며 Extremely Positive 및 Exremely Negative가 상당히 적은 것을 확인할 수 있습니다.
이제 Location에 대해서 분석해보겠습니다.
앞서서 Location에서 null 데이터를 '?' 데이터로 변경하였으니 여기서 '?' 항목을 제외 하고서 상위 10개의 Location을 파악해보았습니다.

London 과 United States 등을 비롯해소 주로 미국 및 영국에서 올라온 트위터가 많은 것을 확인할 수 있었습니다.
다음은 Date에 대해서 분석해보곘습니다.
각 날짜에 Tweet가 얼마나 올라왔는가에 대해서 갯수를 파악하고 이를 그래프로 그렸습니다.
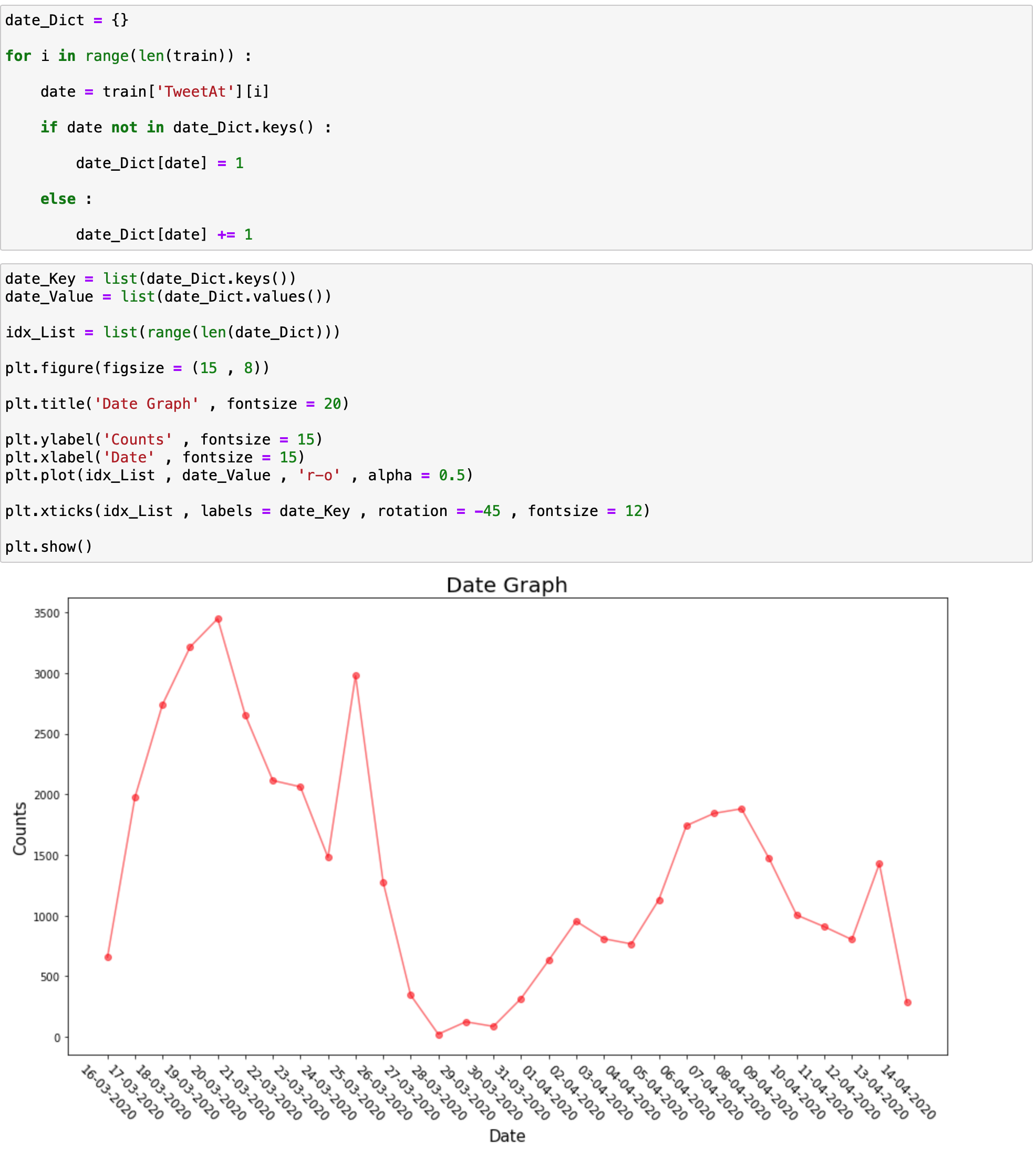
3월 초반에 트위터의 갯수가 많다가 3월 말에 다시 감소하고 4월 초에 다시 증가하는 추세를 보이고 있습니다.
이게 각 감정별로 트위터의 길이를 비교해보겠습니다.

먼저 데이터 Sentiment 별로 구분해서 데이터를 분할하고 리스트에 순차적으로 저장합니다.
아래는 분할된 예시입니다.

리스트의 0번쨰 원소는 Neutral만 있는 데이터인 것을 확인할 수 있습니다.
이제 리스트에 있는 데이터에서 Length를 Box plot으로 그려보면서 비교해보겠습니다.
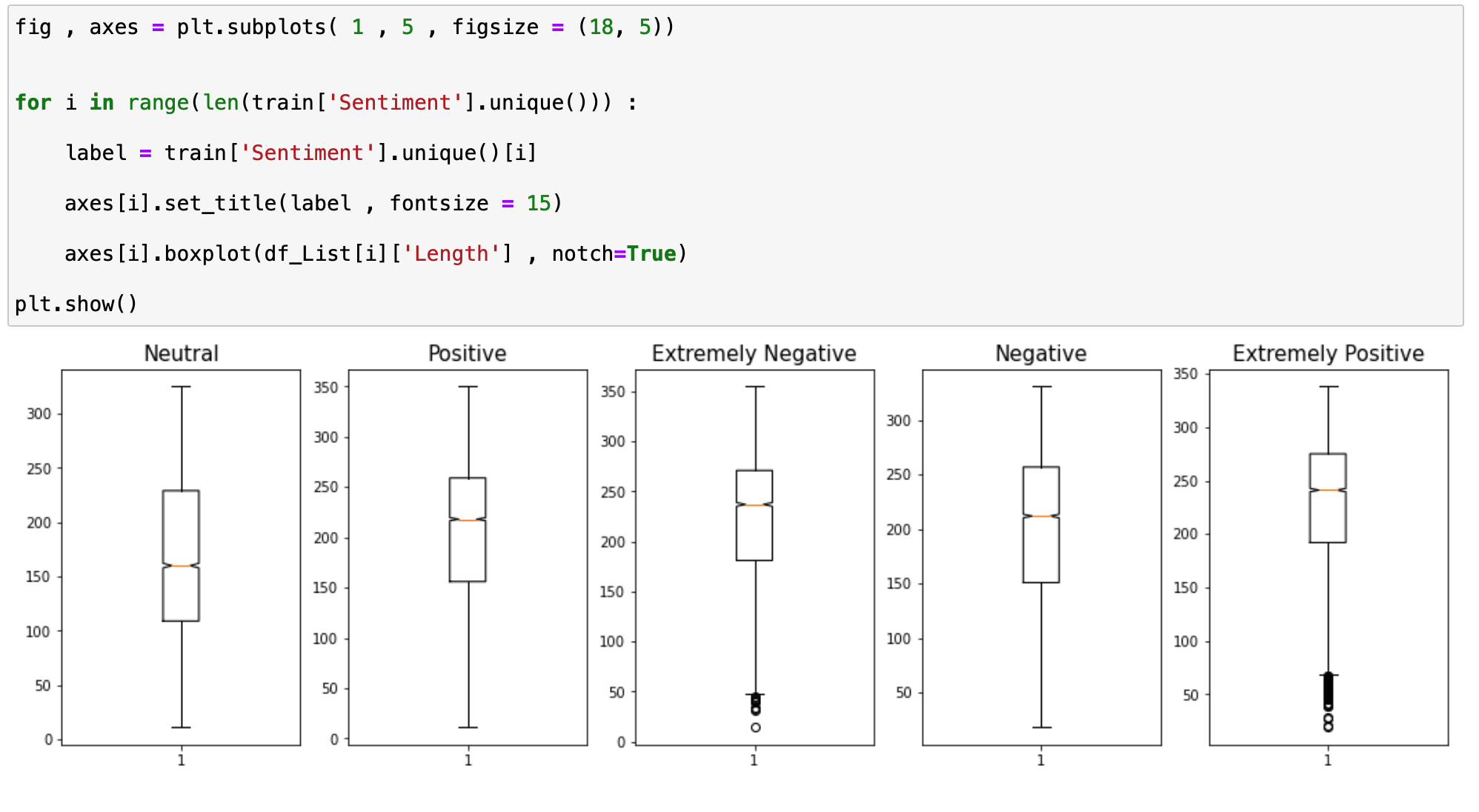
Neutral의 경우보다 감정이 있는 경우 negative , positive 그리고 Extremely Negative 혹은 Positive의 경우 길이가 훨씬 더 긴 트위터가 많이 있다는 것을 확인 할 수 있었습니다.
'Deep Learning' 카테고리의 다른 글
| Deep Learning - Corona Tweets 분석하기 Part3 : 트위터 감정 분석하는 LSTM 기반 모델 만들기 (0) | 2020.10.19 |
|---|---|
| Deep Learning - Corona Tweets 분석하기 Part2 : 텍스트 전처리하기 (0) | 2020.10.19 |
| Deep Learning - LSTM을 이용한 애플의 주식 값 예측하기 (0) | 2020.10.19 |
| Deep Learning - GloVe Embedding Layer을 이용한 Fake News 구별하기 Part2 (0) | 2020.10.10 |
| Deep Learning - GloVe Embedding Layer을 이용한 Fake News 구별하기 Part1 (0) | 2020.10.10 |