데이터 출처 : www.kaggle.com/harlfoxem/housesalesprediction
House Sales in King County, USA
Predict house price using regression
www.kaggle.com
ipynb file : github.com/sangHa0411/DataScience/blob/main/House_Sales.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
Part2에서는 Part1에서 진행한 데이터 분석을 토대로 해서 특성을 추출하고 이를 이용해서 Random Forest를 사용해보겠습니다.
아래는 Part1에서 결정한 최종적으로 사용할 데이터 특성들입니다.
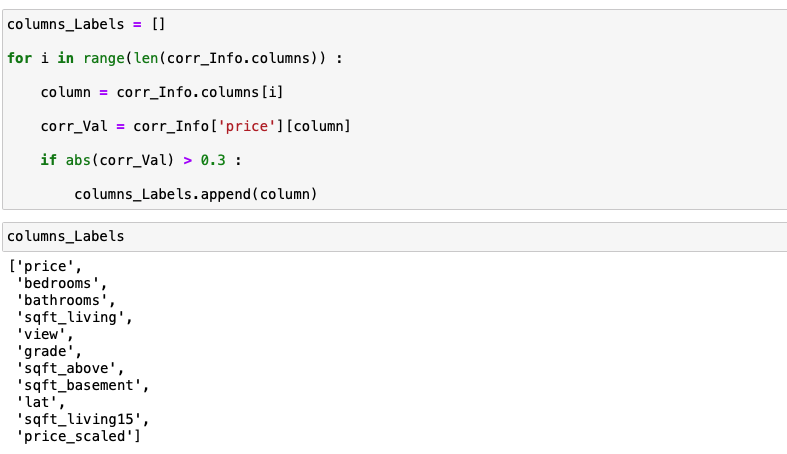
위의 특성들만을 먼저 선택해서 데이터 프레임을 만듭니다.
그 후에 price_scaled 속성을 label로 선정하고 기존 데이터에서 Price와 관련된 데이터 속성을 제거함으로써 데이터와 레이블을 정합니다.

여기서 scikit learn을 이용해서 데이터를 훈련 데이터와 테스트 데이터로 분할합니다.
분할 정도는 80% : 20% 로 데이터를 분할합니다.
그 다음은 데이터를 numpy array로 변경해서 scikit learn의 RandomForest를 학습시킬 수 있도록 해줍니다.

최종적인 데이터 구조는 아래와 같습니다.

sklearn에서 RandomForestRegressor를 불러오고 훈련데이터를 이용해서 RandomForest를 학습시킵니다.

RandomForest 참고 자료 : towardsdatascience.com/understanding-random-forest-58381e0602d2
Understanding Random Forest
How the Algorithm Works and Why it Is So Effective
towardsdatascience.com
위 자료에서 RandomForest에 대해서 알기 쉽게 정리되어있습니다.
이제 훈련된 Random Forest를 이용해서 테스트 데이터를 기반으로 집 값을 예측해보곘습니다.

이제 이 예측 결과와 실제 결과를 그래프로 비교해보겠습니다.

데이터 갯수가 많아서 위 그래프로는 예측이 잘 되어 있는지 없는지 파악이 힘듭니다.
여기서 특정 부분을 확대해서 다시 그려보면 아래와 같습니다.
자세한 코드는 위 github 를 보시면 확인하실 수 있습니다.
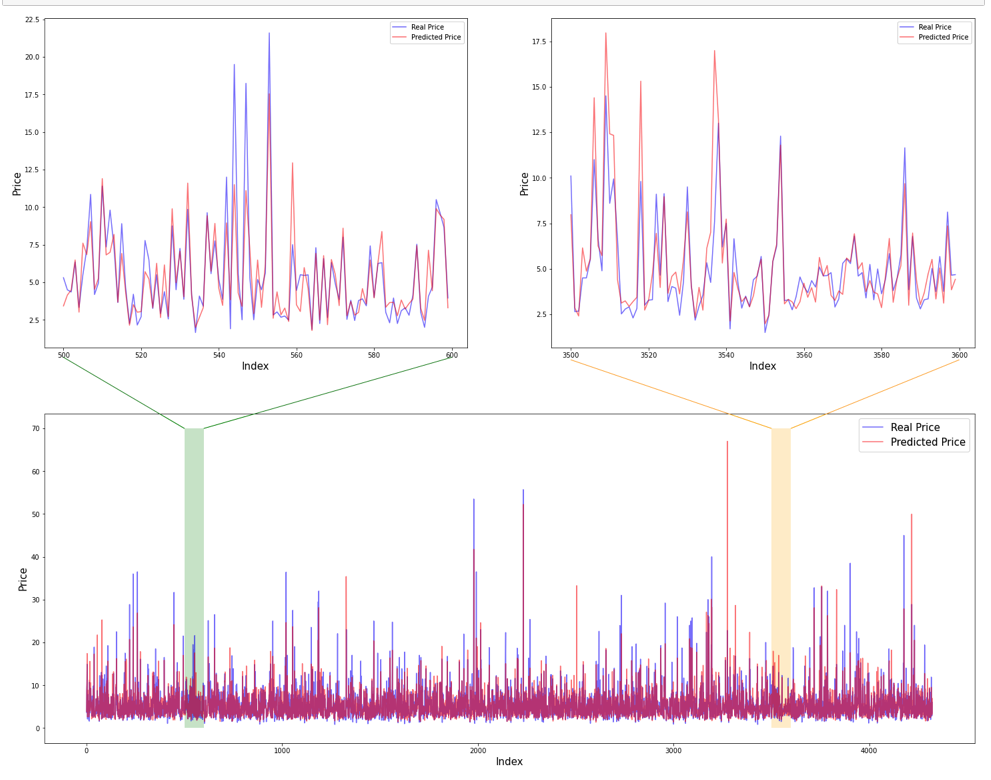
예측이 완전히 맞는 것은 아니지만 그래도 큰 차이 없이 예측이 어느정도 잘 되는 것을 확인할 수 있습니다.
이제 구체적인 수치로써 테스트 데이터의 실제 집 값과 예측 값에 대한 오류 값을 계산하겠습니다.

RMSE 수치로 1.920 값이 된 것을 확인할 수 있습니다.
'Machine Learning' 카테고리의 다른 글
| Machine Learning - Bayesian Linear Regression을 이용한 보험 비용 예측하기 Part1 (0) | 2020.10.10 |
|---|---|
| Machine Learning - Logistic Regression 심장 병 여부 예측하기 (0) | 2020.10.07 |
| Machine Learning - Random Forest 집값 예측하기 Part1 (0) | 2020.10.06 |
| Machine Learning - SVM 마스크 착용 여부 검사하기 (0) | 2020.10.06 |
| Machine Learning - Logistic Regression 연봉 예측하기 Part3 (0) | 2020.10.05 |