Deep Learning - 트위터 감정 분석하기 Part1
Twitter and Reddit Sentimental analysis Dataset
Tweets and Comments extracted from Twitter and Reddit For Sentimental Analysis.
www.kaggle.com
ipynb file : github.com/sangHa0411/DataScience/blob/main/Twitter%20Sentiment%20Analysis.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
이번 포스팅에서는 트위터에 있는 Text를 긍정 , 부정 , 중립 으로 나눌 수 있는 Deep Learning 기반 모델을 만들어 볼려고 합니다.
Part1 에서는 데이터를 분석 및 전처리하고 제가 직접 LSTM 기반 Deep Learning 을 만들어보고
Part2 에서는 이미 훈련되어 있는 GloVe Embedding Layer를 이용해서 만들어보고 Part1와의 성능을 비교해볼려고 합니다.
먼저 데이터를 Pandas를 이용해서 불러오고 데이터의 갯수를 확인합니다.

데이터를 보면 clean_text라 되어 있어 이미 Text 데이터에서 노이즈가 제거가 된 것을 알 수 있습니다.
각 label 클래스와 해당 클래스의 갯수를 파악합니다.

긍정이 가장 많았고 그 다음은 중립이 많았습니다. 부정은 전체 데이터의 21% 정도를 차지하는 것을 확인할 수 있습니다.
다음은 문장의 길이의 히스토그램을 파악합니다.

히스토그램을 보면 트위터의 길이가 대략 50~80 구간이 가장 많은 것을 확인할 수 있지만 대략 230까지 비교적 골고룩 분포하는 것을 확인할 수 있습니다.
이제 Text에서 필요 없는 단어들을 제거하기 위해서 nltk의 stopword 집합을 불러옵니다.

이제 불러온 STOPWORDS를 이용해서 Text를 단어집합으로 바꾸고 해당 단어 집합에서 유효단어 저장해서 새롭게 Text를 만듭니다.

그리고 이러한 유효단어들만으로 만들어진 Text를 이용해서 각 label(긍정 ,중립 , 부정)의 WordCloud를 만들어서 비교 분석해보자 합니다.
다음은 긍정 label의 word cloud 입니다

다음은 중립 label의 word cloud 입니다.

제가 보기에는 2 label의 word cloud가 크게 차이가 없어 보입니다.
다음은 부정 label의 word cloud 입니다.
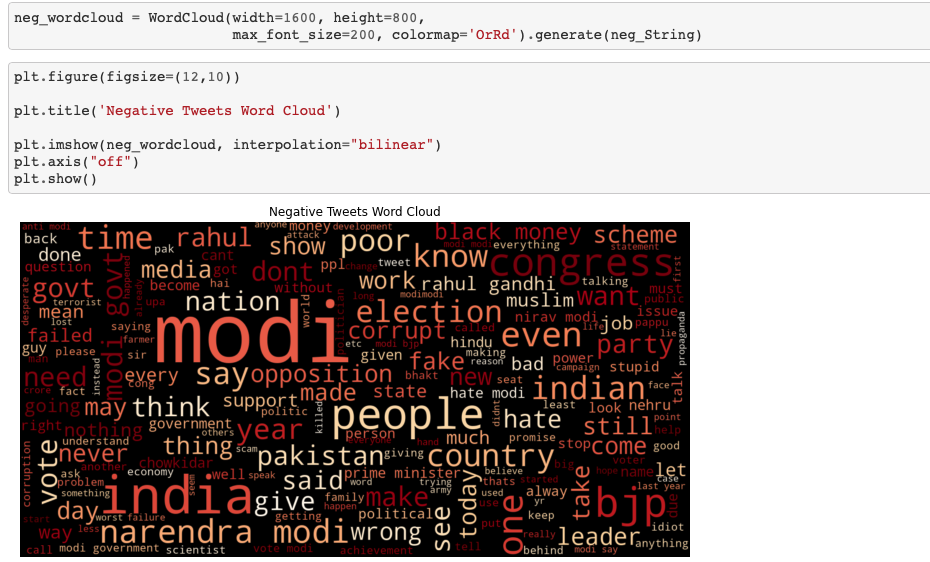
이 word cloud에는 never, wrong, fake , opposition 등의 단어들이 들어있어 긍정 혹은 중립의 word cloud와 차이가 있는 것을 확인할 수 있습니다.
데이터 분석은 이정도로 마치고 이제 데이터 전처리를 할려고 합니다.
각 label로 데이터를 분할하였으니 각 label 당 데이터를 80% , 20% 나누어서 훈련 데이터 및 테스트 데이터에 저장합니다.
저는 긍정을 0 , 중립을 1 , 부정을 2로 인코딩하였습니다.

훈련 및 테스트 데이터가 긍정 a개 , 중립 b개 , 부정 c개 가 섞이지 않고 순서대로 들어있으니 Deep Learning 학습을 위해서 데이터의 순서를 셔플합니다.
훈련 및 테스트 데이터는 단어들의 집합으로 구성되어 있으니 해당 단어를 정수로 인코딩하는 과정이 필요합니다. 이를 위해서 keras의 전처리 도구를 불러옵니다.

훈련 데이터 만을 이용해서 토크나이저 즉 정수 인코딩을 해주는 도구를 학습시킵니다.
해당 토크나이저를 이용해서 훈련 데이터 및 테트스 데이터를 변환하고 훈련 데이터의 최대 길이를 파악합니다.

입력의 길이를 모두 최대 길이인 42로 일치시킵니다.

이제 0 , 1, 2로 인코딩 했던 label들을 one hot 인코딩을 해줍니다.

최종적으로 데이터 전처리 결과 데이터의 구조는 다음과 같습니다.

저는 양방향 LSTM을 이용해서 Keras 모델을 만들어보고자 합니다.


아래는 훈련 과정입니다.
훈련하면서 Validation Loss 가 가장 작은 것을 선택해서 저장하도록 하였습니다.

테스트 데이터로 평가한 결과 정확도가 89% 정도 되는 것을 확인할 수 있습니다.
