Deep Learning - Corona Tweets 분석하기 Part3 : 트위터 감정 분석하는 LSTM 기반 모델 만들기
데이터 출처 : www.kaggle.com/datatattle/covid-19-nlp-text-classification
Coronavirus tweets NLP - Text Classification
Corona Virus Tagged Data
www.kaggle.com
github 주소 : github.com/sangHa0411/DataScience/blob/main/Corona_Tweets.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
Part2에서 한 데이터 전처리를 이용해서 이번 Part3에서는 LSTM을 이용해서 코로나 관련 트위터의 감정 분석을 해보도록 하겠습니다.
먼저 각 감정별로 분류된 데이터를 80 : 20 의 비율로 나누어서 훈련 데이터 및 테스트 데이터에 각각 저장합니다.

여기서 주의할 점은 기존 데이터의 Clean Text는 str 타입이기 때문에 이를 공백을 기준으로 나누어서 word_List 형식으로 훈련 데이터 및 테스트 데이터에 저장해야 한다는 것입니다.

이제 Word List를 Integer List로 변경하기 위해서 즉 정수 인코딩을 위해서 Keras의 Tokenizer를 이용합니다.

이제 훈련된 tokenizer를 이용해서 훈련 데이터 및 테스트 데이터의 word List를 Integer List로 변경합니다.

이제 정수 벡터로 구성이 된 훈련 데이터에 대해서 벡터의 최대 길이 및 길이에 대한 히스토그램을 파악해볼려고 합니다.

최대 길이는 64이고 입력 벡터의 길이가 10 부터 40까지 골고룩 분포되어있는 것을 확인할 수 있습니다.
저는 여기서 50이상은 비율이 적다고 판단하여서 정수로된 벡터의 길이를 모두 50으로 맞추어 주었습니다.

이제 label 데이터에 대해서 0 , 1. 2 로 구성이 되어있는 데이터를 길이가 3인 one hot encoding을 하겠습니다.

이제 마지막으로 데이터를 분할해서 저장할 때 Neutral , Negative , Positive 등으로 순차적으로 저장하였으니 이를 LSTM에 학습시키기 위해서는 무작위로 섞어 주어야 합니다.

이제 최종적으로 입력 데이터가 되는 데이터들의 shape을 확인해보겠습니다.

다음으로 LSTM을 모델을 설계해보도록 하겠습니다.
저는 양방향 LSTM을 이용하였습니다.


먼저 입력과 Word Embedding을 모델에 추가합니다.

그리고 핵심이 되는 LSTM을 모델에 추가합니다.

마지막으로 Dense 즉 Fully Connected Layer를 모델에 추가합니다.
최종적으로 완성된 모델의 구조에 대한 설명입니다.

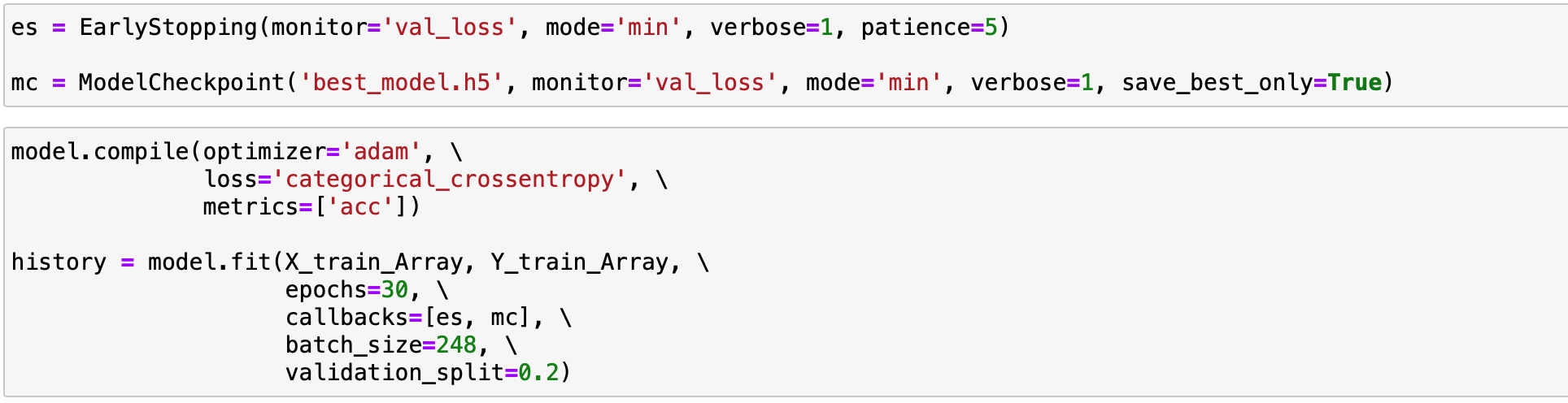
이제 이 모델을 앞서서 만든 데이터를 이용해서 훈련시킵니다.

Validation 기준으로 그래프를 보면 정확도가 0.8 초반대 정도에 있는 것을 확인할 수 있습니다. 또한 Loss가 0.5정도에 있는 것을 확인할 수 있습니다.
이제 최종적으로 테스트 데이터를 이용해서 훈련된 모델의 성능을 측정해보겠습니다.

이로써 저희는 코로나 관련 트위터에 대해서 감정을 분석할 수 있는 LSTM 모델을 만들어 보고 성능을 측정해보았습니다.