Deep Learning - GloVe Embedding Layer을 이용한 Fake News 구별하기 Part2
데이터 출처 : www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset
Fake and real news dataset
Classifying the news
www.kaggle.com
ipynb file :github.com/sangHa0411/DataScience/blob/main/FakeNews_Detection.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
참고 자료 : www.kaggle.com/madz2000/nlp-using-glove-embeddings-99-87-accuracy
NLP using GloVe Embeddings(99.87% Accuracy)
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
Part1 에서는 Fake News 및 True News 에 대한 데이터 분석을 마치고 기사에서 Text 전처리를 해서 유효단어들만을 추려냈습니다.
이제 이를 이용해서 RNN을 설계하고 학습할 계획입니다.
먼저 데이터와 레이블을 구분합니다.

이를 이용해서 훈련데이터 및 테스트 데이터를 80% : 20% 로 분할합니다.

여기서 X_train 및 X_test는 string으로 데이터가 구성이 되어 있으니 다시 유효 단어 리스트로 분할을 해야 합니다.

이제 유효 단어 리스트들을 정수 리스트로 인코딩위해서 필요한 라이브러리를 불러오고 이용합니다.

훈련 데이터의 유효 단어 리스트로 tokenizer를 학습합니다.

훈련 결과를 보시면 많이 나온 단어 순서대로 정수가 1부터 시작해서 mapping이 되는 것을 알 수 있습니다.
이제 이 유효 단어 리스트들을 정수 리스트로 바꾸고 벡터의 크기를 300으로 동일하게 해줍니다.
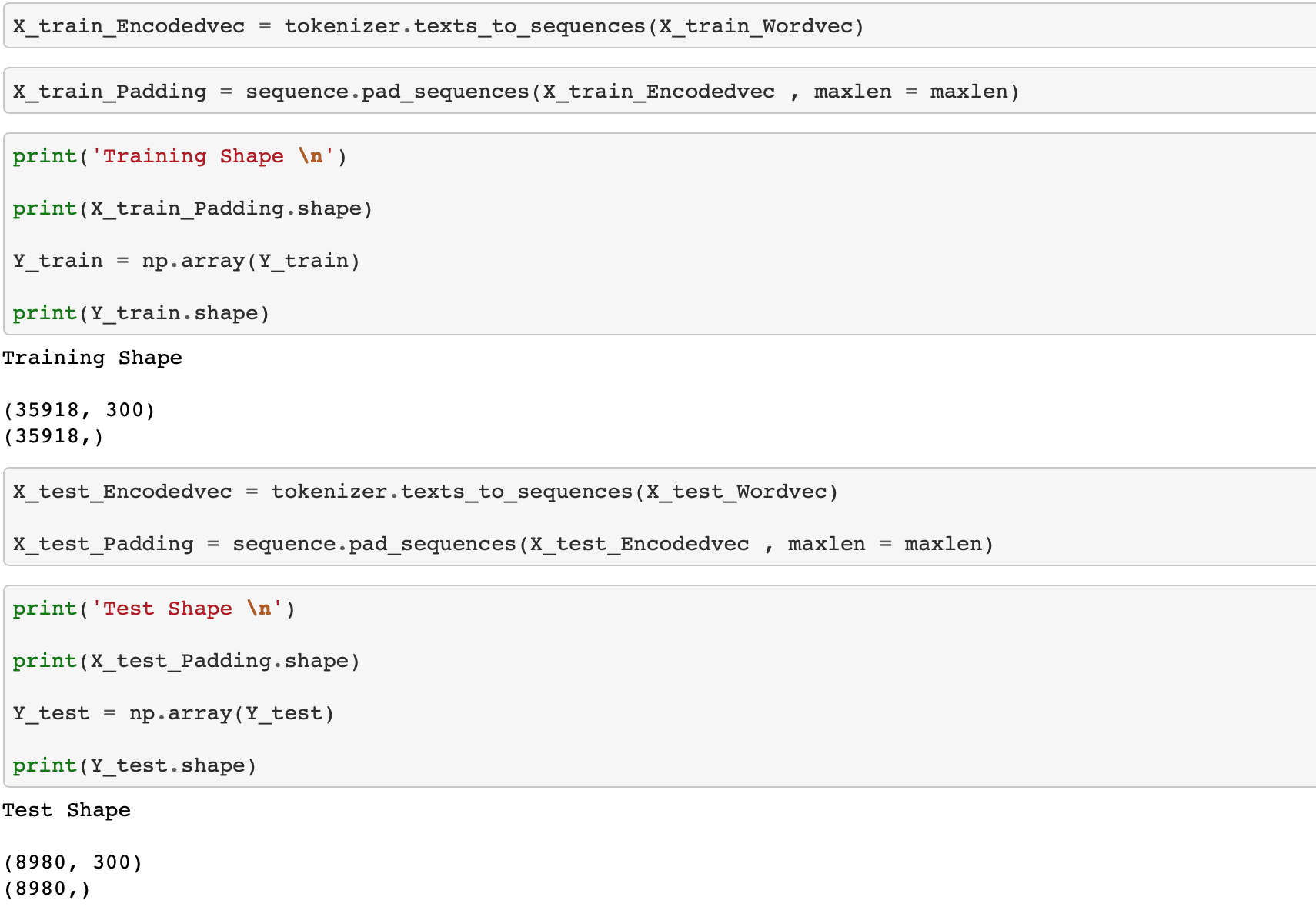
이제 위에서 학습한 tokenizer의 word_index와 GloVe Embedding txt 파일을 이용해서 Embedding Layer를 사전 제작해보곘습니다.

먼저 txt 파일을 불러와서 한줄 한줄씩 읽습니다.
한줄씩 읽으면서 첫번째 와 나머지를 구분해서 저장하는데 이는 txt파일이 [단어 , (길이가 100인 벡터)] 로 구성이 되어있기 때문입니다.
이를 이용해서 dictionary 구조로 key는 단어 value는 길이가 100인 vector가 되도록 저장을 해줍니다.
이렇게 만든 embedding_dict와 앞에서 만든 tokenizer와 word_index와 연결해서 Embedding_Layer를 만들 계획입니다.
길이가 100인 벡터로 사전이 훈련이 되어 있으므로 길이를 100으로 고정합니다.

그리고 word_index에 있는 단어 하나하나 돌아가면서 위에서 만든 embedding_Dict의 key에서 같은 단어가 등장하면 tokenizer의 정수 값 -> 길이가 100인 벡터로 값을 저장합니다.
즉 정수로 구성된 벡터가 입력되면 해당 값을 인덱스로 해서 embedding_matrix의 해당 인덱스의 길이가 100인 벡터를 불러오는 구조입니다.
이제 RNN을 학습할 모든 준비를 마쳤습니다.
먼저 필요한 라이브러리를 불러옵니다.

이제 모델을 만듭니다.

Model에 사전에 만든 Embeddin Layer를 넣는데 이미 훈련이 되어있는 것이므로 훈련이 불가능하도록 설정합니다.

ReducaROnPlateau함수는 아래의 참고자료를 보시면 이해하실 수 있으실 것입니다.
참고자료 : teddylee777.github.io/tensorflow/keras-콜백함수-vol-01
[Keras] 콜백함수 (1) - 학습률(learning rate): ReduceLROnPlateau
[Keras] 콜백함수 (1) - 학습률(learning rate): ReduceLROnPlateau에 대하여 알아보겠습니다.
teddylee777.github.io
다음은 모델의 학습 과정입니다.

다음은 model의 정확도에 대한 학습 과정을 그래프로 그린 것입니다.

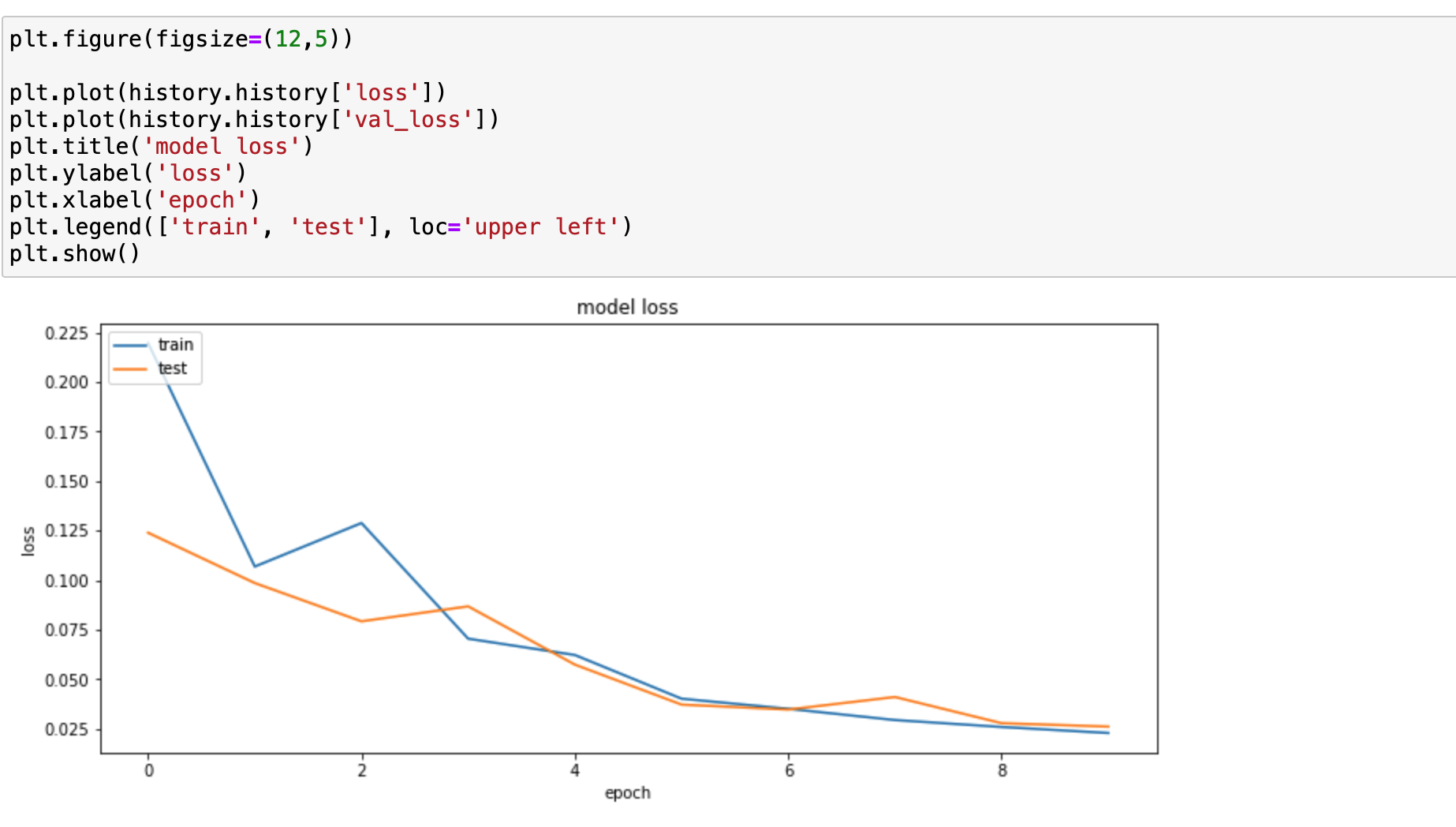
다음은 modeld loss에 대한 학습 과정을 그래프로 그린 것입니다.
모델의 최종 평가를 해보겠습니다.

테스트 데이터에 대한 정확도가 99%가 되면서 매우 높은 정확도를 가지는 것을 확인할 수 있습니다.