Machine Learning - Random Forest 집값 예측하기 Part1
데이터 출처 : www.kaggle.com/harlfoxem/housesalesprediction
House Sales in King County, USA
Predict house price using regression
www.kaggle.com
ipynb file : github.com/sangHa0411/DataScience/blob/main/House_Sales.ipynb
sangHa0411/DataScience
Contribute to sangHa0411/DataScience development by creating an account on GitHub.
github.com
Part1 에서는 데이터 분석하도록 해보겠습니다
Part2에서는 분석한 데이터를 토대로 해서 Random Forest를 이용해서 집 값을 예측할 수 있도록 해보겠습니다.
이전 까지는 Machine Learning 문제에서 분류 문제를 살펴봤다면 이번에는 집 값을 수치로 예측하는 회귀 문제에 대해서 다루어볼려고 합니다.
회귀 문제를 바로 다루기 앞서서 먼저 데이터에 대한 분석을 하도록 하겠습니다.
먼저 Pandas를 이용해서 데이터를 불러왔습니다.

위의 데이터 구조를 보면 날짜, 가격 침실 갯수 등등에 여러가지 정보가 있는 것을 확인할 수 있습니다,
여기서 Target Data는 Price 인 것을 확인할 수 있고 나머지 데이터와 이 Target Data와의 연관성을 파악해서 회귀 문제에 사용할지 안할지 결정하고자 합니다.
먼저 Target Data인 Price에 대해서 분포를 확인해보고자 합니다.

위는 히스토그램을 이용한 집 값의 분포를 시각화한 결과입니다. 0 ~ 1 (단위 1e6) 사이에 Price가 주로 분포되어있다는 것을 확인할 수 있습니다.
이제 날짜와 집 값에 대해서 연관성이 있는지 알아볼려고 합니다.
먼저 Date에 대한 정보에 뒷부분 T000000 있으니 이를 삭제해줍니다.

그리고 각 날짜에 대한 House Price의 평균 값을 구하고자 합니다.

Key 는 Date Value는 Price로 되어있는 구조입니다.
새로운 Date가 들어오면 해당 집 값을 Value에 저장합니다. 그리고 이미 Date가 있는 경우라면 기존의 집 값과 새로 들어온 집 값의 평균을 저장합니다.
저장을 마친 이후에는 Key 기준, 즉 날짜 기준으로 데이터를 정렬합니다.

모든 Date에 대해서 Xlabel에 표시하면 겹치는 부분이 많아서 읽기가 어려우니 특정 Date만을 Xlabel에 표기하도록 설정합니다.

위는 각 날짜에 대한 집 값 또한 집 값들의 평균을 구하고 그래프를 그린 결과입니다.
제가 보기에는 집 값과 날짜는 크게 상관이 없어 보입니다.
다음은 집 값과 Bedrooms 갯수에 대한 연관성을 분석해보고자 합니다.

보면 Bedrooms가 많을 수록 집 값들이 조금 더 높게 분포되어있는 것을 확인할 수 있습니다. 따라서 Bedrooms 와 집 값은 연관성이 있다고 판단할 수 있습니다.
Bathrooms와 집 값에 대한 연관성을 분서해보고자 합니다.

Bathrooms가 클수록 집 값이 어느정도 올라가는 양상을 확인할 수 있습니다.
Waterfront와 집 값사이의 연관성을 분석하겠습니다.
먼저 Waterfront가 있는지 없느지 여부에 따라서 데이터를 분할합니다.

그리고 분할된 집합의 집 값의 히스토그램을 겹쳐 그립니다.
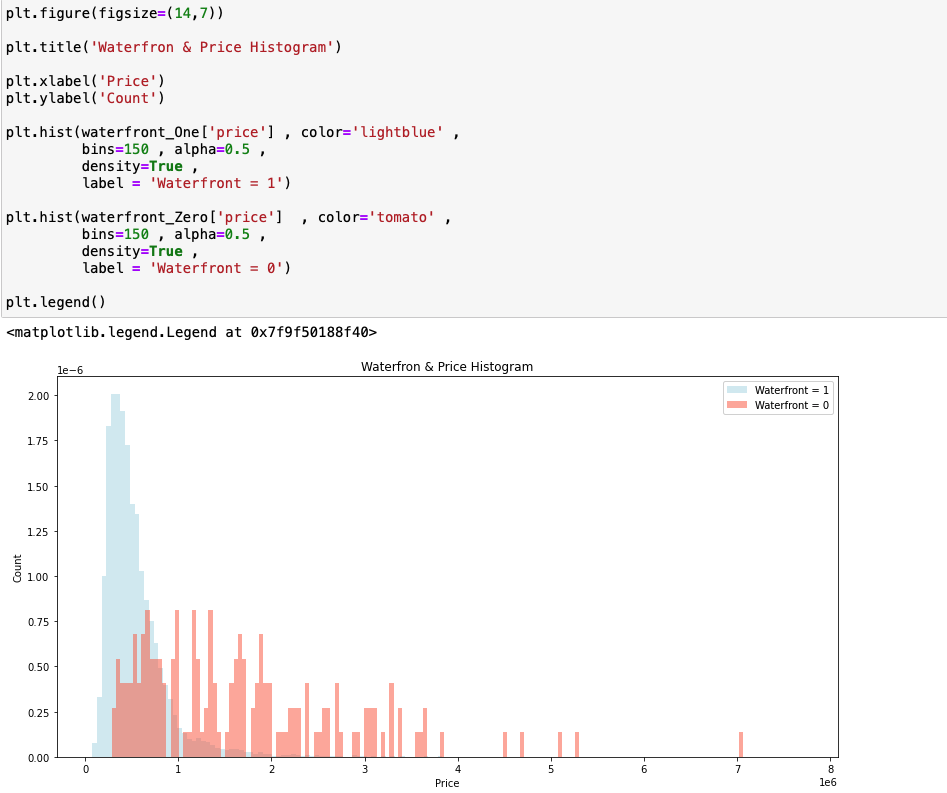
Xlabel이 집 값을 의미하기 때문에 Waterfrontrk 0인 집들의 값이 1인 집들의 값보다 더 비싸다는 것을 파악할 수 있습니다.
다음은 View와 집 값의 연관성을 분석해보겠습니다.

View가 4일 때는 다른 값일 때 보다 비싼 집 값들이 많이 있다는 것을 확인할 수 있습니다.
이제 Grade와 집 값의 연관성을 분석해보곘습니다.

한 눈에 봐도 알 수 있듯이 Grade가 높을 수록 집 값이 비싸지는 것을 확인할 수 있습니다.
이제 전체적으로 집 값과 나머지 데이터 속성들에 대해서 상관 관계를 구체적인 수치로써 분석할려고 합니다.

속성이 많기 때문에 집 값과 다른 데이터 속성들간에 상관 관계를 파악하기가 어렵습니다.
여기서 집 값과 관련된 수치만 불러오면 다음과 같습니다.

상관 관계 수치가 -1에 가까울 수록 반비례하는 관계 1에 가까울 수록 정비례하는 관계
0에 가까우면 해당 속성은 집 값과 연관성이 없다라는 것을 의미합니다.
이 수치를 기반으로해서 절댓값이 0.3보다 큰 속성만을 이용해서 Machine Learning - Random Forest에 이용하고자 합니다.
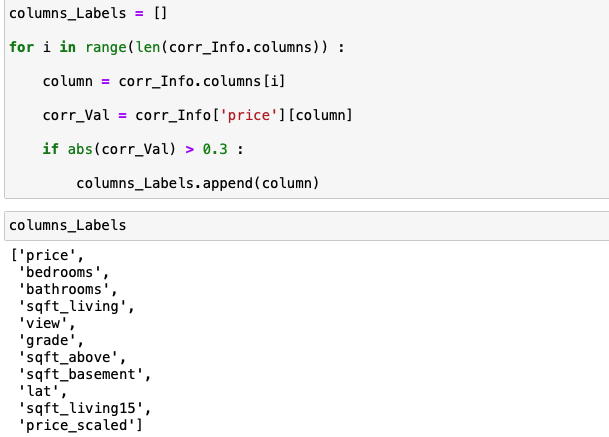
이제 이 데이터 분석을 토대로해서 Part2에서 특성 추출 및 데이터 분할을 하고 Random Forest를 이용해서 집 값을 예측하는 모델을 만들어보겠습니다.